作为一名热爱阅读的技术人,我在微信读书上积累了数百本书的读书笔记。但每次想在自己的博客上展示阅读清单时,都要手动复制粘贴,效率极低。于是,我决定开发一个自动化的书单同步方案,实现从微信读书到个人博客的一键同步。
项目背景与需求分析
痛点
作为一个长期在微信读书上阅读的用户,我面临以下几个问题:
- 数据孤岛:微信读书的书单数据封闭在 App 内,没有官方 API 供开发者使用
- 手动同步繁琐:想要在个人博客展示书单,需要一本本手动录入
- 图片外链问题:微信读书的封面图片有防盗链,直接引用会失效
- 阅读进度不同步:想展示每本书的阅读进度和阅读时长
目标
实现一个完整的同步方案:
- Chrome 扩展:拦截微信读书网页版数据,提取书单信息
- 后端服务:接收数据,下载封面图片并上传到自己的 OSS
- 数据库存储:保存书籍信息、阅读进度、阅读时长等
技术架构设计
系统架构分为三个层次:
前端实现:Chrome Extension
Manifest V3 配置
Chrome 扩展采用 Manifest V3 版本,核心配置如下:
{
"manifest_version": 3,
"name": "微信读书书单同步",
"version": "1.0.0",
"permissions": [
"storage",
"notifications",
"activeTab"
],
"host_permissions": [
"https://weread.qq.com/*"
],
"content_scripts": [
{
"matches": ["https://weread.qq.com/web/shelf"],
"js": ["content.js"],
"world": "ISOLATED"
}
],
"background": {
"service_worker": "background.js"
}
}
|
关键点:world: "ISOLATED" 是 Manifest V3 的要求,用于隔离扩展代码和页面代码。
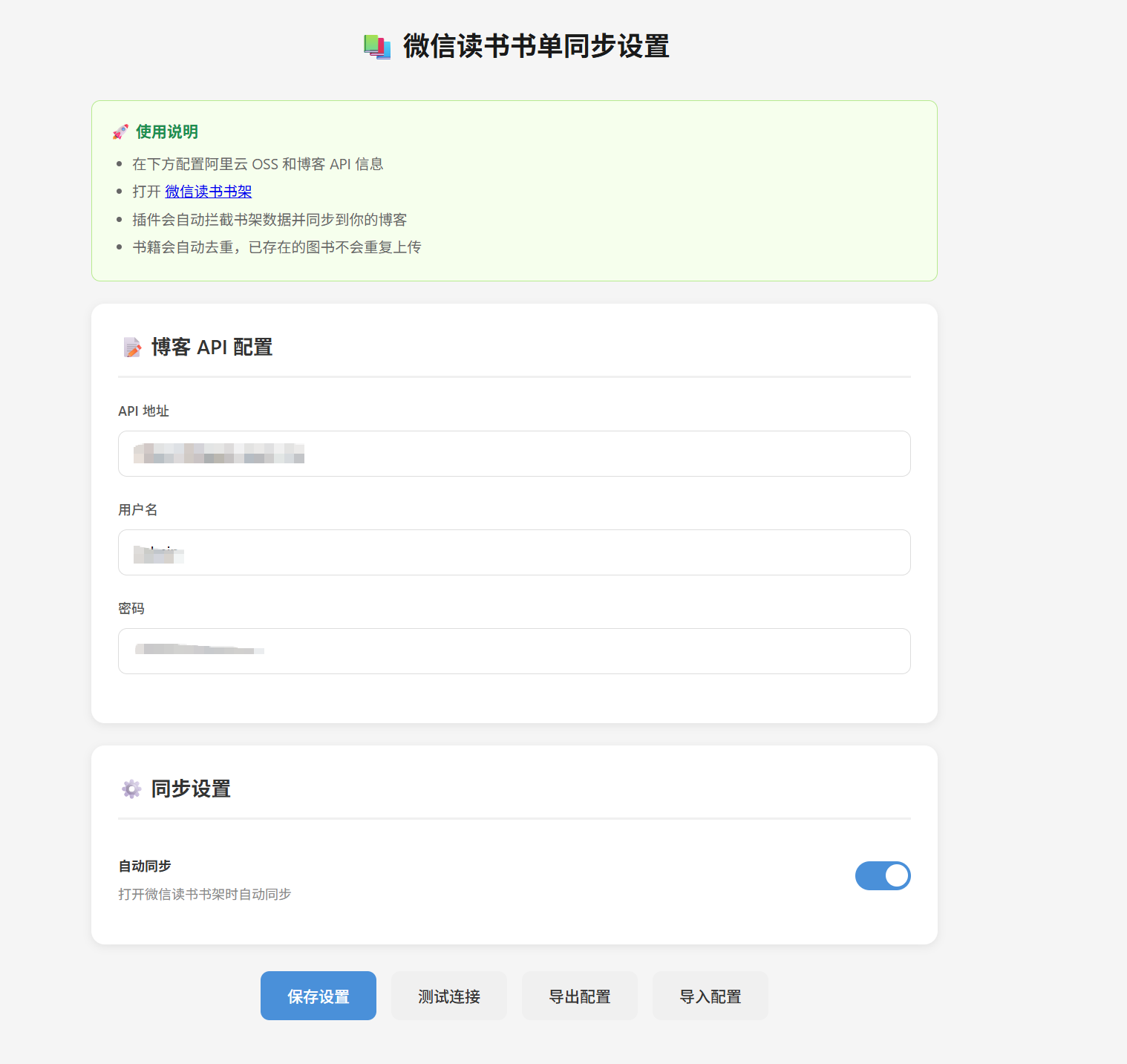
扩展的配置页面如下图所示,只需填写博客 API 的地址和登录凭证即可:
数据拦截与提取
微信读书的书架数据通过 /web/shelf/sync API 获取。我们需要在页面上下文中注入脚本拦截这个请求:
const originalFetch = window.fetch;
window.fetch = async function(...args) {
const [url, config] = args;
if (url.includes('/web/shelf/sync')) {
const response = await originalFetch.apply(this, args);
const clonedResponse = response.clone();
const data = await clonedResponse.json();
const books = extractBooksFromAPIData(data);
window.postMessage({
type: 'WEREAD_SHELF_DATA',
data: { booksAndArchives: books }
}, '*');
return response;
}
return originalFetch.apply(this, args);
};
|
数据解析与合并
微信读书的 API 返回的数据结构分为两部分:books(书籍基础信息)和 bookProgress(阅读进度),需要通过 bookId 进行关联:
function extractBooksFromAPIData(data) {
const books = [];
const progressMap = {};
if (data.bookProgress && Array.isArray(data.bookProgress)) {
data.bookProgress.forEach(progress => {
if (progress.bookId) {
progressMap[progress.bookId] = {
readingTime: progress.readingTime || 0,
progress: progress.progress || 0,
updateTime: progress.updateTime || 0
};
}
});
}
if (data.books && Array.isArray(data.books)) {
data.books.forEach(book => {
if (book.bookId && book.title) {
const progressInfo = progressMap[book.bookId] || {};
books.push({
bookId: String(book.bookId),
title: book.title,
author: book.author ? String(book.author).replace(/\n/g, ' ').trim() : '',
cover: book.cover ? book.cover.replace(/\\u002F/g, '/') : '',
readingTime: progressInfo.readingTime || 0,
updateTime: progressInfo.updateTime || 0,
progress: progressInfo.progress ? String(progressInfo.progress) : ''
});
}
});
}
return { booksAndArchives: books };
}
|
用户选择界面
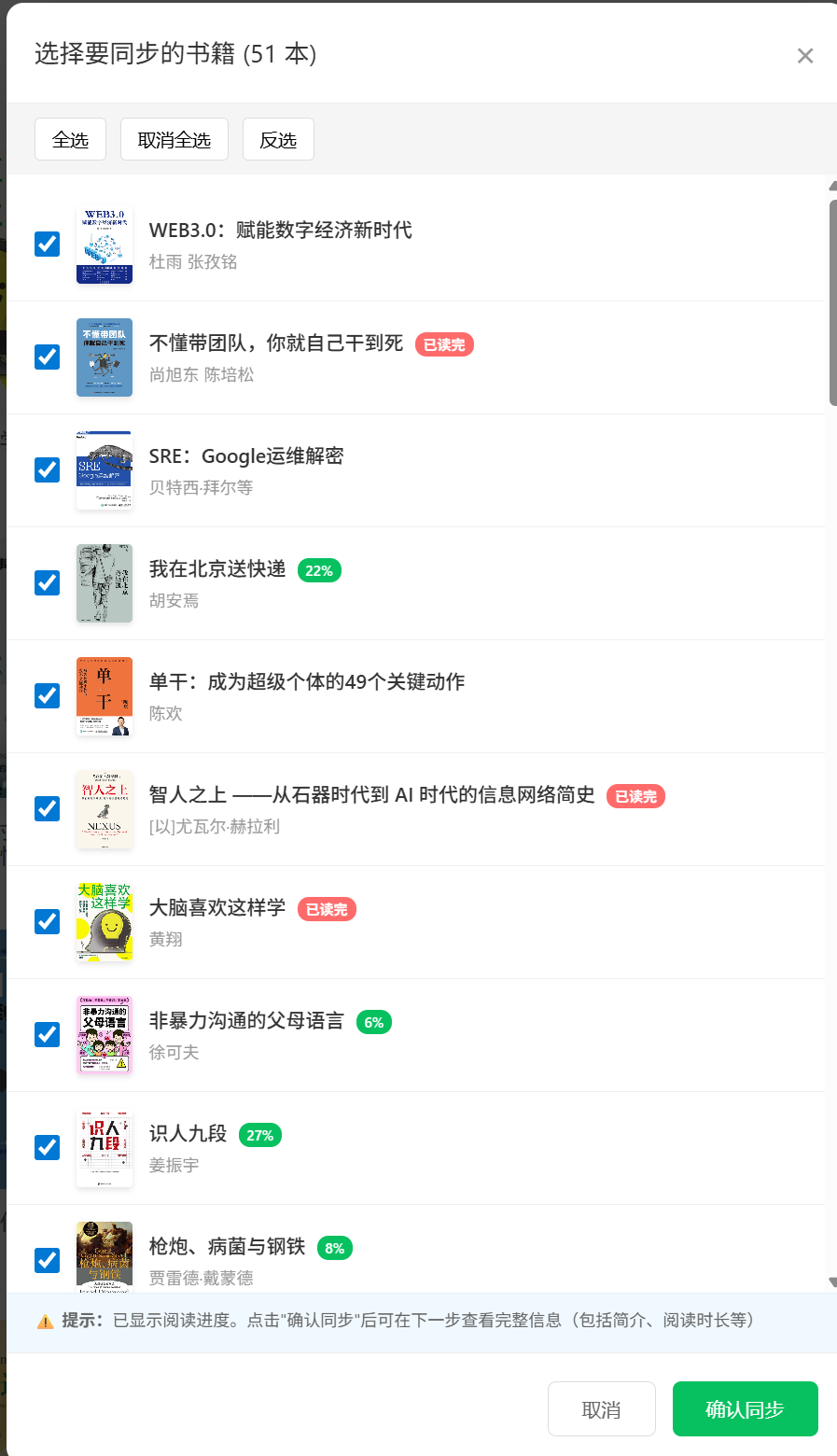
为了不让用户一次性同步所有书籍(可能包含已弃读的书),我设计了一个可视化的选择界面:
async function createSelectionUI(books) {
const modal = document.createElement('div');
modal.id = 'weread-sync-selection-modal';
modal.style.cssText = `
position: fixed; top: 0; left: 0; width: 100%; height: 100%;
background: rgba(0,0,0,0.7); z-index: 999999;
display: flex; justify-content: center; align-items: center;
`;
const bookList = document.createElement('div');
books.forEach((book, index) => {
const item = document.createElement('div');
item.innerHTML = `
<input type="checkbox" class="weread-sync-checkbox"
data-index="${index}" checked>
<img src="${book.cover}" style="width: 40px; height: 56px;">
<div>
<div>${book.title}</div>
<div style="color: #999;">${book.author || '未知作者'}</div>
</div>
<span style="background: #07C160; color: white; padding: 2px 8px;
border-radius: 10px; font-size: 11px;">
${book.progress}%
</span>
`;
bookList.appendChild(item);
});
return new Promise((resolve) => {
document.getElementById('weread-sync-confirm').addEventListener('click', () => {
const selectedIndexes = Array.from(document.querySelectorAll('.weread-sync-checkbox:checked'))
.map(cb => parseInt(cb.dataset.index));
const selectedBooks = selectedIndexes.map(i => books[i]);
resolve({ action: 'confirm', books: selectedBooks });
});
});
}
|
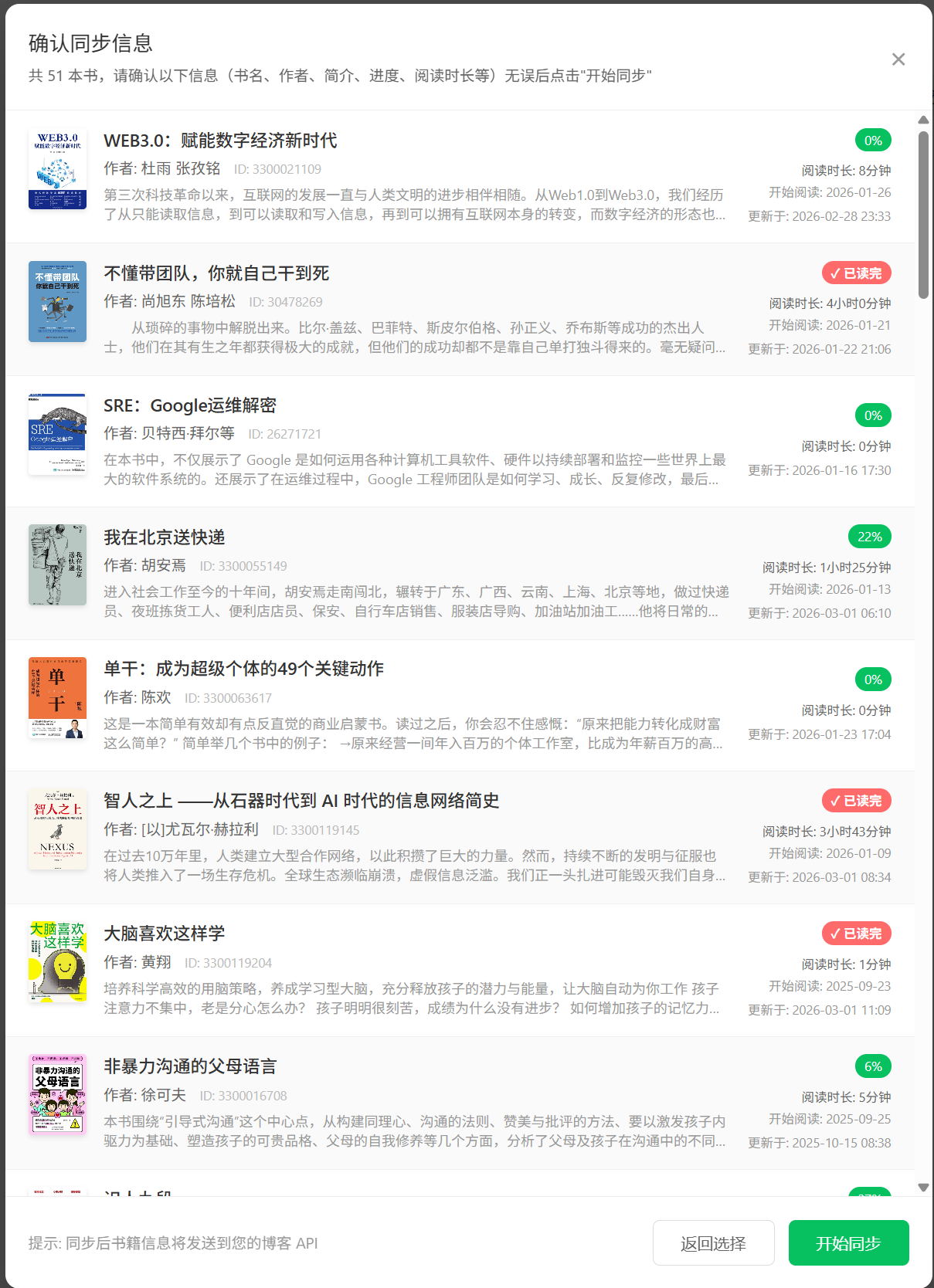
实际效果如下图所示,用户可以直观地看到每本书的封面、标题、作者和阅读进度:
后端实现:Go + Gin + OSS
后端采用 Go 语言 + Gin 框架实现,主要功能包括:接收扩展数据、下载封面图片、上传到阿里云 OSS、数据持久化。
数据模型设计
type Book struct {
ID uint `json:"id" gorm:"primaryKey"`
BookID string `json:"bookid" gorm:"uniqueIndex;comment:书籍唯一标识"`
Title string `json:"title" gorm:"not null;index;comment:书名"`
Author string `json:"author" gorm:"comment:作者"`
Cover string `json:"cover" gorm:"comment:封面图片URL"`
Desc string `json:"desc" gorm:"type:text;comment:书籍描述"`
Rating int `json:"rating" gorm:"default:0;comment:评分1-5"`
Progress int `json:"progress" gorm:"default:0;comment:阅读进度百分比0-100"`
ReadingDuration int `json:"reading_duration" gorm:"default:0;comment:阅读时长(秒)"`
LastReadingTime CustomTime `json:"last_reading_time" gorm:"comment:最后阅读时间"`
ReadTime string `json:"read_time" gorm:"comment:阅读时间,格式YYYY-MM"`
SortKey string `json:"sort_key" gorm:"index;comment:排序键"`
CreatedAt time.Time `json:"created_at"`
UpdatedAt time.Time `json:"updated_at"`
}
|
自定义时间类型
由于微信读书返回的是 Unix 时间戳,而后端数据库存储的是 datetime,需要一个自定义类型来处理转换:
const TimeLayout = "2006-01-02 15:04:05"
type CustomTime struct {
time.Time
}
func (ct *CustomTime) UnmarshalJSON(data []byte) error {
str := string(data)
if str == "null" {
ct.Time = time.Time{}
return nil
}
if len(str) >= 2 && str[0] == '"' && str[len(str)-1] == '"' {
str = str[1 : len(str)-1]
}
parsed, err := time.Parse(TimeLayout, str)
if err != nil {
return err
}
ct.Time = parsed
return nil
}
|
OSS 服务封装
type OSSService struct {
client *oss.Client
bucket *oss.Bucket
config config.OSSConfig
httpClient *http.Client
}
func (s *OSSService) DownloadAndUploadImage(imageURL string, bookID string) (string, error) {
if s.config.CustomDomain != "" && strings.Contains(imageURL, s.config.CustomDomain) {
return imageURL, nil
}
data, contentType, err := s.downloadImage(imageURL)
if err != nil {
return "", fmt.Errorf("下载图片失败: %w", err)
}
objectKey := s.generateObjectKey(bookID, contentType)
err = s.uploadToOSS(objectKey, data, contentType)
if err != nil {
return "", fmt.Errorf("上传图片到 OSS 失败: %w", err)
}
return s.getAccessURL(objectKey), nil
}
func (s *OSSService) downloadImage(imageURL string) ([]byte, string, error) {
req, err := http.NewRequest("GET", imageURL, nil)
if err != nil {
return nil, "", err
}
req.Header.Set("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36")
req.Header.Set("Referer", "https://weread.qq.com/")
resp, err := s.httpClient.Do(req)
if err != nil {
return nil, "", err
}
defer resp.Body.Close()
data, err := io.ReadAll(resp.Body)
if err != nil {
return nil, "", err
}
return data, resp.Header.Get("Content-Type"), nil
}
|
API Handler 实现
func (h *BookHandler) CreateBook(c *gin.Context) {
var req struct {
BookID string `json:"bookid" binding:"required"`
Title string `json:"title" binding:"required"`
Author string `json:"author"`
Cover string `json:"cover"`
Desc string `json:"desc"`
Rating int `json:"rating"`
Progress int `json:"progress"`
ReadingDuration int `json:"reading_duration"`
LastReadingTime models.CustomTime `json:"last_reading_time"`
ReadTime string `json:"read_time"`
}
if err := c.ShouldBindJSON(&req); err != nil {
c.JSON(http.StatusBadRequest, gin.H{"code": 400, "message": err.Error()})
return
}
coverURL := req.Cover
if h.OSS != nil && h.OSS.IsEnabled() && req.Cover != "" {
newURL, err := h.OSS.DownloadAndUploadImage(req.Cover, req.BookID)
if err == nil {
coverURL = newURL
}
}
var existing models.Book
if err := h.DB.Where("book_id = ?", req.BookID).First(&existing).Error; err == nil {
updates := make(map[string]interface{})
if coverURL != "" && coverURL != existing.Cover {
updates["cover"] = coverURL
}
if req.ReadingDuration > 0 && req.ReadingDuration != existing.ReadingDuration {
updates["reading_duration"] = req.ReadingDuration
}
if !req.LastReadingTime.IsZero() {
updates["last_reading_time"] = req.LastReadingTime.Time
}
if len(updates) > 0 {
h.DB.Model(&existing).Updates(updates)
}
c.JSON(http.StatusOK, gin.H{
"code": 0,
"message": "success",
"data": existing,
"action": "updated",
})
return
}
book := models.Book{
BookID: req.BookID,
Title: req.Title,
Author: req.Author,
Cover: coverURL,
Desc: req.Desc,
Rating: req.Rating,
Progress: req.Progress,
ReadingDuration: req.ReadingDuration,
LastReadingTime: req.LastReadingTime,
ReadTime: req.ReadTime,
}
h.DB.Create(&book)
c.JSON(http.StatusOK, gin.H{
"code": 0,
"message": "success",
"data": book,
"action": "created",
})
}
|
遇到的问题与解决方案
1. CORS 跨域问题
问题:Chrome Extension 在 Service Worker 中无法直接访问微信读书的 CDN 图片(cdn.weread.qq.com)。
解决:将图片下载和上传逻辑移到后端,前端只传递 URL。
2. Manifest V3 的限制
问题:Manifest V3 要求 world: "ISOLATED",导致 chrome.runtime API 在页面上下文中不可用。
解决:使用 window.postMessage 作为 content script 和 injected script 之间的通信桥梁。
3. 时间格式转换
问题:微信读书返回 Unix 时间戳(秒),后端需要转换为 2006-01-02 15:04:05 格式存储。
解决:在扩展端进行格式化,避免后端解析复杂度:
const date = new Date(updateTime * 1000);
const lastReadingTime = `${date.getFullYear()}-${String(date.getMonth() + 1).padStart(2, '0')}-${String(date.getDate()).padStart(2, '0')} ${String(date.getHours()).padStart(2, '0')}:${String(date.getMinutes()).padStart(2, '0')}:${String(date.getSeconds()).padStart(2, '0')}`;
|
4. 字段命名不一致
问题:Go 的 binding 标签要求 bookid(小写),而错误信息显示需要 BookID(大写驼峰)。
解决:统一使用小写 + 下划线的 JSON 字段名,与数据库字段保持一致。
部署与使用
扩展安装
- 打开 Chrome 扩展管理页面
chrome://extensions/
- 开启开发者模式
- 点击”加载已解压的扩展程序”
- 选择项目目录
后端部署
go build -o blog-api ./cmd
export OSS_ACCESS_KEY_ID=your-access-key-id
export OSS_ACCESS_KEY_SECRET=your-access-key-secret
export OSS_BUCKET=your-bucket-name
export OSS_REGION=oss-cn-shanghai
export OSS_CUSTOM_DOMAIN=https://file.awen.me
./blog-api
|
使用效果
配置完成后,在 微信读书网页版 点击”同步书架”按钮:
- 弹出书籍选择界面,显示每本书的阅读进度
- 选择要同步的书籍,点击确认
- 扩展自动提取数据并发送到后端
- 后端下载封面图片上传到 OSS
- 收到桌面通知提示同步结果
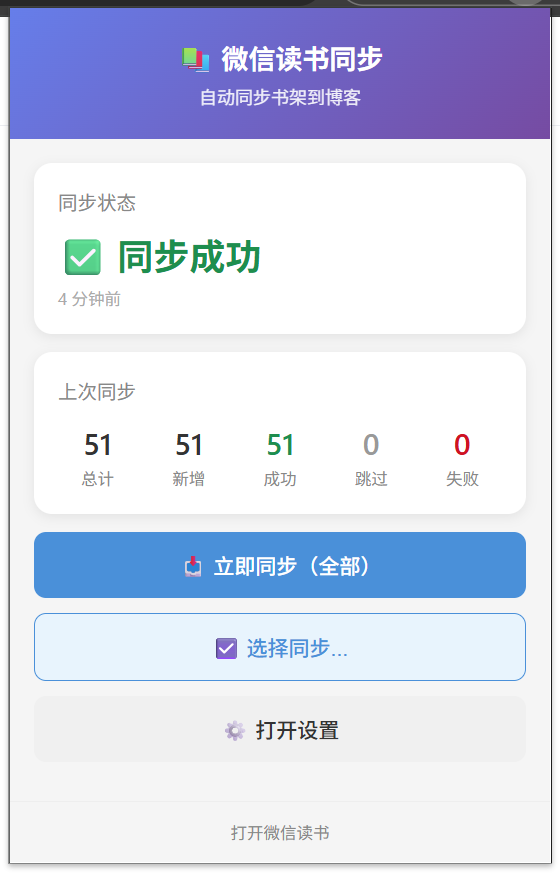
同步完成后会收到桌面通知,显示本次同步的统计信息:
总结
通过这个项目,我实现了一个完整的”数据抓取-处理-存储”链路:
技术亮点:
- Chrome Extension Manifest V3 的最佳实践
- 前后端分离的架构设计
- 阿里云 OSS 的图片托管方案
- Go 语言的简洁高效后端实现
可扩展性:
- 可以轻松适配其他阅读平台(如豆瓣读书、Kindle 等)
- 支持批量导入和增量更新
- 阅读数据可视化(后续可添加统计图表)
参考链接:“}} (Assistant: 现在修改其他几篇文章。先查看微信读书那篇的上下文。 (Assistant: 现在修改微信读书那篇文章。我早就已经修改过了,让我检查一下是否还有其他文章需要修改。从之前的grep结果来看,还有几篇文章包含
评论
0 条评论