前言 写博客这么多年,积累了将近 800 篇文章,涵盖前端、后端、DevOps、自动化、AI 等多个领域。但问题是——我自己都经常找不到以前写过的内容 。每次想查某个技术点的实现方案,都得翻目录、搜关键词,效率极低。
最近 RAG(检索增强生成)很火,心想能不能把自己的博客做成一个专属知识库问答系统 ?说干就干,花了一下午时间,基于 LangChain + Milvus + 阿里云百炼 搭了一套完整的方案,效果出乎意料地好。
技术选型
组件
选型
说明
向量数据库
Milvus 2.6
高性能、支持分布式,通过 K8s 部署在局域网
Embedding
阿里云百炼 text-embedding-v3
1024 维,中文效果优秀
LLM
阿里云百炼 qwen-turbo
流式输出,响应速度快
框架
LangChain
负责文档切分、向量检索、提示词工程
后端
FastAPI
轻量高效,原生支持 SSE 流式响应
前端
纯 HTML/CSS/JS
参考知乎直答的简洁风格
整体架构 ┌─────────────────┐ ┌──────────────┐ ┌─────────────────┐
核心实现 1. 博客文档导入 Milvus 首先需要把博客的 Markdown 文件清洗、切分、向量化后存入 Milvus。
from langchain_text_splitters import RecursiveCharacterTextSplitterfrom langchain_community.embeddings import DashScopeEmbeddingsfrom pymilvus import MilvusClient, DataTypedef extract_text_from_markdown (md_content: str ) -> str :r'^---\s*\n.*?---\s*\n' , '' , md_content, flags=re.DOTALL)r'{%.*?%}' , '' , md_content, flags=re.DOTALL)"html.parser" )return soup.get_text(separator="\n" ).strip()800 ,150 ,"\n## " , "\n### " , "\n\n" , "\n" , "。" , ";" , " " , "" ],for i in range (0 , len (split_docs), 25 ):25 ]for d in batch])"blog_knowledge" , data=[...])
2. 两阶段检索 + Rerank 直接向量检索的 Top-5 可能不够精准,我改成了先粗排再精排 的两阶段策略:
粗排 :从 Milvus 召回 20 篇候选文档(COSINE 相似度 ≥ 0.45)精排 :用阿里云百炼的 gte-rerank 模型对候选文档重新排序,取 Top-5
RETRIEVE_TOP_K = 20 5 0.45 def retrieve_docs (query: str ):for d, s in docs_with_score if s >= SIMILARITY_THRESHOLD]if not candidates:return []for d, _ in candidates]"gte-rerank" ,for d in docs],False ,for r in resp.output.results:"index" ]if r["relevance_score" ] >= 0.3 :return ranked
Rerank 后回答质量明显提升,尤其是模糊查询时,能把真正相关的文档排到前面。
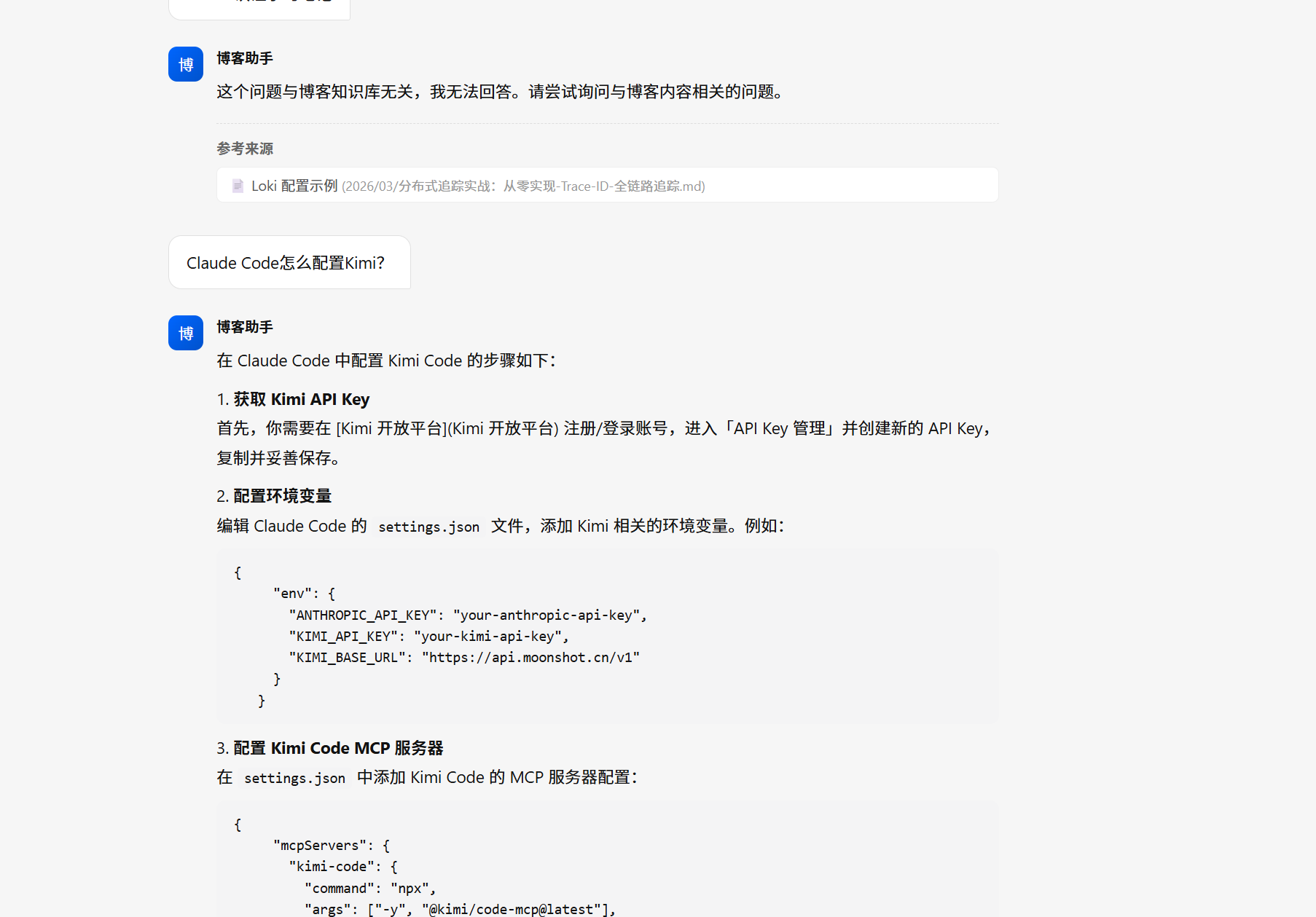
3. 严格的提示词工程 这是整个系统的灵魂——必须限定只能回答与知识库相关的问题 ,防止 LLM hallucination(幻觉)。
SYSTEM_PROMPT = """你是一个专业的博客知识库问答助手。你的唯一信息来源是下方提供的博客知识库片段。 【规则】 1. 你只能根据提供的知识库片段回答问题。 2. 如果知识库片段中没有相关信息,或者用户的问题与博客内容完全无关, 你必须直接回答:"这个问题与博客知识库无关,我无法回答。请尝试询问与博客内容相关的问题。" 3. 不要编造知识库片段中没有的信息。 4. 回答时要清晰、简洁、有条理。 【知识库片段】 {context} 请根据以上知识库片段回答用户问题。"""
4. 多轮对话与会话记忆 支持多轮追问,会话历史超过 10 轮后自动压缩成摘要,避免上下文过长消耗 Token。
MAX_HISTORY_TURNS = 10 def build_messages (session_id: str , user_question: str , context: str ):"turns" : [], "compressed_summary" : "" })if len (session["turns" ]) >= MAX_HISTORY_TURNS:"turns" ])"compressed_summary" ] = summary"turns" ] = []"role" : "system" , "content" : SYSTEM_PROMPT.format (context=context)}]if session["compressed_summary" ]:"role" : "system" , "content" : f"此前对话摘要:{session['compressed_summary' ]} " })for turn in session["turns" ]:"role" : "user" , "content" : turn["user" ]})"role" : "assistant" , "content" : turn["bot" ]})"role" : "user" , "content" : user_question})return messages
5. FastAPI 流式接口 使用 SSE(Server-Sent Events)实现打字机效果,用户体验更自然。
@app.post("/api/chat" async def chat (request: ChatRequest ):async def event_stream ():if not docs:yield f"data: {{'type': 'token', 'content': '拒绝回答'}}\n\n" return set ()for doc in docs:"source" , "" )if key and key not in seen:"title" : ..., "source" : key})async for chunk in llm.astream(messages):yield f"data: {{'type': 'token', 'content': chunk.content}}\n\n" yield f"data: {{'type': 'sources', 'sources': sources}}\n\n" yield "data: {'type': 'done'}\n\n" return StreamingResponse(event_stream(), media_type="text/event-stream" )
6. 前端设计 参考了知乎直答的简洁风格,纯 HTML/CSS/JS 实现,无框架依赖:
首页 :大标题 + 圆角搜索框 + 推荐问题标签对话页 :左侧可折叠历史会话栏 + 右侧消息区域暗色/亮色主题切换 :右上角一键切换,状态保存在 localStorageMarkdown 渲染 :集成 marked.js,支持代码块、表格、列表、粗体等消息区域滚动 :chat-messages 固定高度,内容超出时独立滚动,输入框始终固定在底部
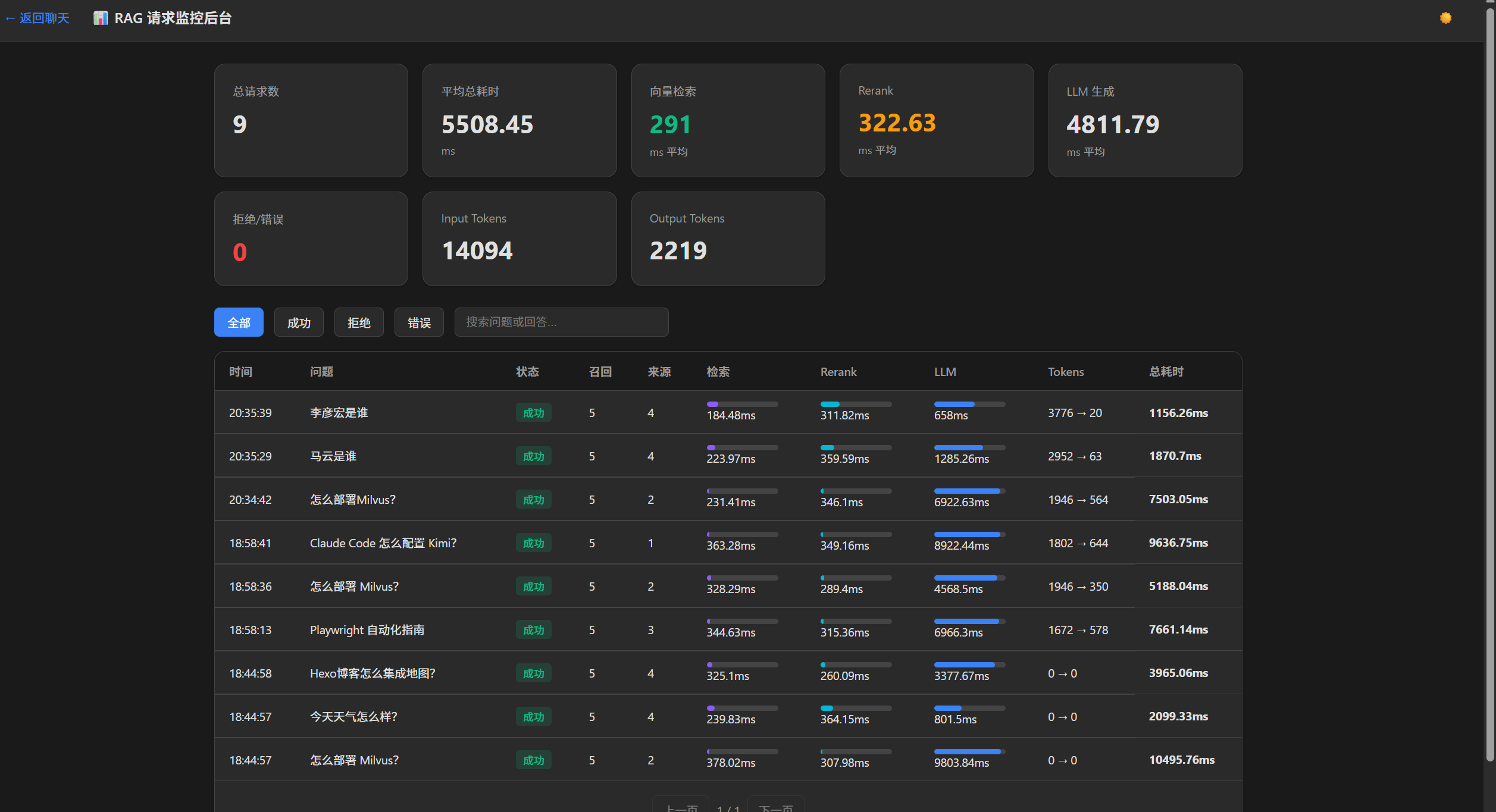
7. 自建监控后台 不想依赖 Langfuse 这类第三方监控平台,我用 SQLite + 纯前端自己搭了一个监控后台,零额外依赖。
每次 /api/chat 请求自动落库,记录:
各阶段耗时(向量检索、Rerank、LLM 生成)
召回文档数与相似度分数
去重后的来源文档
Input / Output Token 消耗 请求状态(成功/拒绝/错误)
后台页面 /admin 提供:
顶部统计卡片:总请求数、平均耗时、各阶段平均耗时、Token 总量
请求列表:带迷你耗时条形图,一眼看出瓶颈在哪一步
状态筛选 + 关键词搜索 + 分页
点击展开详情:耗时分解、来源文档、Token 消耗、输入输出内容
实测数据发现 Input Token 远大于 Output Token ——因为每次请求都要把系统 Prompt + 检索到的 5 篇文档上下文一起塞进 LLM。这也解释了为什么向量检索的文档数量需要控制,上下文越长 Token 成本越高。
踩坑记录 1. Milvus 端口不是默认的 19530 我的 Milvus 是通过 K8s NodePort 暴露的,实际端口是 30001 。用 kubectl get svc 才能确认:
$ kubectl get svc | grep milvus
2. LangChain Milvus 的 score 含义 LangChain 的 similarity_search_with_score() 返回的 score 对 COSINE metric 来说是 similarity(越大越相似) ,不是 distance。我一开始按 distance 的逻辑设了 0.4 阈值,结果把高相关文档全过滤掉了。
3. 同一篇文章的 chunk 去重 一篇博客被切分成多个文本块存入向量库后,检索时可能命中同一篇文章的多个 chunk。如果不做去重,参考来源会重复显示 N 次。解决方案是在后端用 set() 对 source 路径去重。
4. Flex 布局中消息区域撑大页面 一开始消息多了之后会把输入框顶出视口。根本原因是 Flex Column 布局中子元素默认 min-height: auto,即使设置了 flex: 1 和 overflow-y: auto 也不会收缩。
解决方案:给 chat-messages 和它的父容器 main-area 都加上 min-height: 0,同时把 html, body 设为 height: 100%; overflow: hidden,彻底禁止页面级滚动。
5. 全量导入 720 篇文章很慢 720 篇文章切分成 4400+ 个 chunk,逐个调用 Embedding API 非常慢。优化方案:
DashScope 的 embed_documents() 内部已做批量处理
手动分批次(每批 25 条)直接写入 Milvus
最终全量导入约需 6-8 分钟
项目结构 blog_rag/ / /
效果验证
✅ 相关问题 :”怎么部署 Milvus?” → 检索到博客内容,分步骤详细回答
❌ 无关问题 :”今天天气怎么样?” → 直接拒绝:”这个问题与博客知识库无关…”
下一步
全量导入 :目前只导入了最新 60 篇测试,后续把 720 篇全部灌入图片/链接引用 :答案中提到的图片和外链可以原样展示部署上线 :用 Docker Compose 打包,方便迁移
总结 整个项目从 0 到可用只花了不到半天时间,核心得益于:
LangChain 把 RAG 流程抽象得非常干净Milvus 向量检索性能足够强阿里云百炼 的 Embedding + LLM 一套 API 搞定,不用折腾多个平台
最满意的是那个提示词限定 ——让 LLM 老老实实只回答博客里有的东西,不会瞎编。这在做个人知识库时非常关键。
评论
0 条评论