最近我需要将某个运动网站(RQ Run)上的个人训练记录同步到我的 Hexo 博客中。由于该网站需要登录才能查看详细数据,并且登录过程包含验证码,因此我使用 Node.js 版的 Playwright 编写了一个自动化脚本,结合阿里云 OCR 服务识别验证码,实现了数据的自动抓取,并通过 EJS 模板在博客上进行展示。
本文将详细讲解整个实现过程。
1. 技术选型
- Playwright: 微软开源的自动化测试工具,支持 Chromium、Firefox 和 WebKit。相比 Puppeteer,它更现代、更稳定,且支持多种浏览器。
- 阿里云 OCR: 用于识别登录时的图片验证码。
- Hexo: 静态博客框架,利用其
_data 数据文件功能存储抓取到的 JSON 数据。
2. 环境准备
首先初始化项目并安装必要的依赖:
npm install playwright @alicloud/ocr-api20210707 @alicloud/openapi-client @alicloud/tea-util @alicloud/darabonba-stream
npx playwright install chromium
|
3. 编写抓取脚本 (rq_scraper.js)
脚本的核心逻辑分为三步:模拟登录、识别验证码、抓取数据。
3.1 初始化浏览器
为了避免被网站检测为机器人,我们需要配置 UserAgent 和 HTTP Headers。此外,Playwright 的 headless: true 模式可以让脚本在后台静默运行。
const browser = await chromium.launch({
headless: true
});
const context = await browser.newContext({
userAgent: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/144.0.0.0 Safari/537.36',
viewport: { width: 1920, height: 1080 },
extraHTTPHeaders: {
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
}
});
|
3.2 验证码识别与自动重试
登录页面包含一个点击可刷新的验证码图片。我们先截图保存验证码,然后调用阿里云 OCR 接口进行识别。如果识别出的验证码不是4位数,或者登录提交后页面没有跳转(说明验证码错误),脚本会自动刷新验证码并重试。
async function recognizeCaptchaAliyun(filePath) {
const bodyStream = Stream.default.readFromFilePath(filePath);
const recognizeAllTextRequest = new ocr_api20210707.RecognizeAllTextRequest({
body: bodyStream,
type: 'Advanced'
});
}
let loginSuccess = false;
let attempts = 0;
while (!loginSuccess && attempts < 5) {
await captchaElement.screenshot({ path: 'captcha.png' });
let code = await recognizeCaptchaAliyun('captcha.png');
if (code.length === 4) {
await page.fill('#login_code', code);
await loginBtn.click();
try {
await page.waitForNavigation({ timeout: 10000 });
loginSuccess = true;
} catch (e) {
console.log('登录超时或失败,重试...');
}
} else {
await captchaElement.click();
}
}
|
3.3 数据抓取 (API 拦截 vs 页面解析)
最初我尝试直接解析 HTML 表格,但发现效率较低且容易受页面结构变化影响。经过分析网络请求,发现网站通过 API 获取 JSON 数据。于是我改为直接在浏览器上下文中调用该 API。
这里使用了 page.evaluate 在浏览器内部执行 fetch 请求,这样可以直接利用浏览器已登录的 Cookie 状态,无需手动提取 Cookie。
const apiData = await page.evaluate(async () => {
const allData = [];
let page = 1;
const limit = 50;
let totalPages = 1;
while (page <= totalPages) {
const response = await fetch(`https://www.rq.run/Dc/Api?_=User/Record/get_list&page=${page}&limit=${limit}...`);
const json = await response.json();
if (page === 1) {
totalPages = Math.ceil(json.data.total / limit);
}
allData.push(...json.data.list);
page++;
await new Promise(r => setTimeout(r, 200));
}
return allData;
});
|
3.4 数据保存
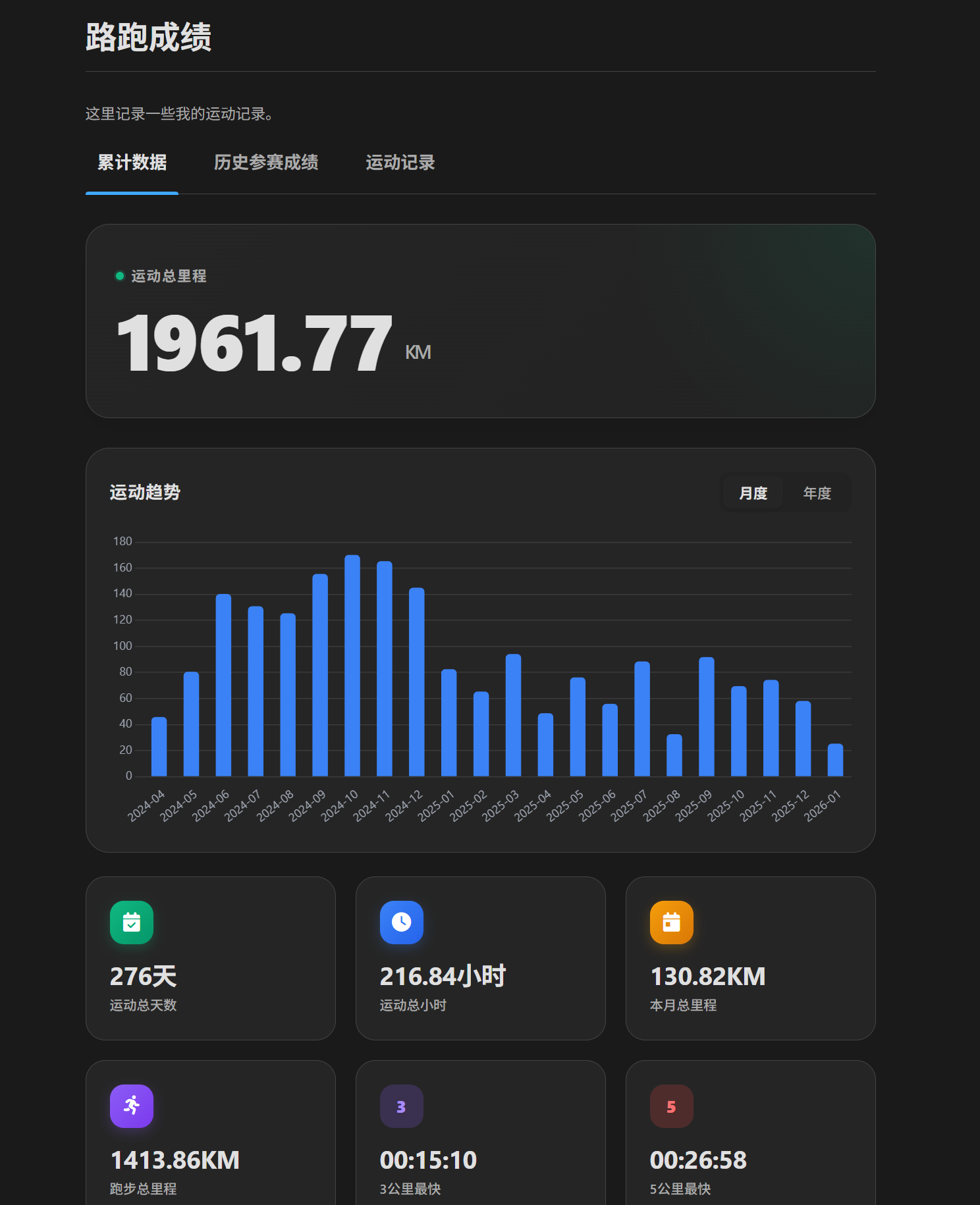
抓取到的数据被保存到 Hexo 的数据目录 source/_data/rq_data.json 中。Hexo 会自动将该文件加载为 site.data.rq_data,供模板使用。
4. 前端展示 (Hexo + EJS)
在 Hexo 的布局文件 (layout/running.ejs) 中,我增加了一个“运动记录”的选项卡。由于数据量较大(可能几百条),一次性渲染会很长,因此我在前端实现了分页功能。
4.1 数据预处理
在 EJS 中,我先对数据进行了清洗和排序(按时间倒序)。
<%
var rqData = site.data.rq_data || [];
rqData.sort(function(a, b) {
return new Date(b.training_at).getTime() - new Date(a.training_at).getTime();
});
%>
|
4.2 客户端分页渲染
为了更好的用户体验,我将数据通过 data- 属性注入到 HTML 中,并使用 JavaScript 进行分页渲染。
const records = JSON.parse(document.getElementById('raw-data').textContent);
const pageSize = 10;
function renderPage(page) {
const start = (page - 1) * pageSize;
const end = start + pageSize;
const pageData = records.slice(start, end);
const html = pageData.map(item => `
<div class="record-card">
<div class="date">${item.training_at}</div>
<div class="distance">${item.distance} km</div>
<div class="pace">${item.avg_speed}</div>
</div>
`).join('');
container.innerHTML = html;
}
|
5. 总结
通过 Playwright 和阿里云 OCR,我们成功攻克了带验证码的模拟登录难题;通过直接调用后端 API,我们提高了数据抓取的效率和稳定性。最终结合 Hexo 的数据驱动能力,实现了一个自动化的个人运动数据展示页面。
如果你也有类似的需求,不妨尝试一下这个方案!
文章作者:阿文
版权声明:本博客所有文章除特别声明外,均采用
CC BY-NC-SA 4.0 许可协议。转载请注明来自
阿文的博客!
评论
0 条评论