"""
Paraformer 实时语音识别服务
使用阿里云 DashScope Python SDK
"""
import os
import json
import asyncio
import threading
import queue
import logging
import time
from fastapi import APIRouter, WebSocket, WebSocketDisconnect
logger = logging.getLogger(__name__)
router = APIRouter()
DASHSCOPE_API_KEY = os.getenv("DASHSCOPE_API_KEY", "")
if DASHSCOPE_API_KEY:
import dashscope
dashscope.api_key = DASHSCOPE_API_KEY
class ASRClient:
"""封装 ASR 客户端,处理缓冲和识别"""
def __init__(self, client_id: str):
self.client_id = client_id
self.audio_buffer = bytearray()
self.result_queue = queue.Queue()
self.recognition = None
self.recognition_thread = None
self.final_text = ""
self.complete_event = threading.Event()
def start_recognition(self):
"""启动语音识别"""
from dashscope.audio.asr import (
Recognition, RecognitionCallback, RecognitionResult
)
class Callback(RecognitionCallback):
def __init__(self, client):
self.client = client
def on_open(self):
logger.info(f"[CLIENT {self.client.client_id}] DashScope 连接打开")
def on_close(self):
logger.info(f"[CLIENT {self.client.client_id}] DashScope 连接关闭")
def on_complete(self):
logger.info(f"[CLIENT {self.client.client_id}] 识别完成")
self.client.result_queue.put({"type": "complete"})
self.client.complete_event.set()
def on_error(self, result: RecognitionResult):
msg = result.message if hasattr(result, 'message') else str(result)
logger.error(f"[CLIENT {self.client.client_id}] 识别错误: {msg}")
self.client.result_queue.put({"type": "error", "error": msg})
self.client.complete_event.set()
def on_event(self, result: RecognitionResult):
try:
sentence = result.get_sentence()
if sentence and isinstance(sentence, dict):
text = sentence.get("text", "")
is_final = RecognitionResult.is_sentence_end(sentence)
if text:
logger.info(f"识别: '{text}' (final={is_final})")
if is_final:
self.client.final_text += text
self.client.result_queue.put({
"type": "final", "text": text
})
else:
self.client.result_queue.put({
"type": "partial",
"text": self.client.final_text + text
})
except Exception as e:
logger.error(f"处理事件错误: {e}")
callback = Callback(self)
self.recognition = Recognition(
model='paraformer-realtime-8k-v2',
format='pcm',
sample_rate=8000,
callback=callback
)
def run():
try:
if self.audio_buffer:
self.recognition.send_audio_frame(bytes(self.audio_buffer))
self.audio_buffer.clear()
self.recognition.start()
except Exception as e:
logger.error(f"识别线程错误: {e}")
self.result_queue.put({"type": "error", "error": str(e)})
self.complete_event.set()
self.recognition_thread = threading.Thread(target=run, daemon=True)
self.recognition_thread.start()
def add_audio(self, audio_data: bytes):
"""添加音频数据"""
try:
if (self.recognition and
hasattr(self.recognition, '_running') and
self.recognition._running):
self.recognition.send_audio_frame(audio_data)
else:
self.audio_buffer.extend(audio_data)
except Exception as e:
self.audio_buffer.extend(audio_data)
def stop(self):
"""停止识别"""
if self.recognition:
try:
self.recognition.stop()
except:
pass
if self.recognition_thread:
self.recognition_thread.join(timeout=2.0)
@router.websocket("/ws/voice")
async def voice_websocket(websocket: WebSocket):
"""WebSocket 实时语音识别"""
await websocket.accept()
if not DASHSCOPE_API_KEY:
await websocket.send_json({
"type": "error", "error": "未配置 DASHSCOPE_API_KEY"
})
await websocket.close()
return
client_id = str(id(websocket))
client = ASRClient(client_id)
recognition_started = False
result_task = None
try:
await websocket.send_json({
"type": "ready", "message": "请发送音频数据"
})
async def send_results_realtime():
"""从 result_queue 获取识别结果并实时发送给客户端"""
result_count = 0
last_result_time = time.time()
while True:
try:
msg = client.result_queue.get_nowait()
result_count += 1
last_result_time = time.time()
await websocket.send_json(msg)
if msg.get("type") in ["complete", "error"]:
await asyncio.sleep(2.0)
while True:
try:
msg = client.result_queue.get_nowait()
await websocket.send_json(msg)
except queue.Empty:
break
break
except queue.Empty:
time_since_last = time.time() - last_result_time
if time_since_last > 30:
break
await asyncio.sleep(0.05)
continue
except Exception as e:
logger.error(f"发送结果错误: {e}")
break
while True:
try:
data = await asyncio.wait_for(websocket.receive(), timeout=0.5)
if isinstance(data, dict):
msg_type = data.get('type')
if msg_type == 'websocket.receive':
text_data = data.get('text')
if text_data:
try:
msg = json.loads(text_data)
if msg.get("type") == "start":
if not recognition_started:
client.start_recognition()
recognition_started = True
result_task = asyncio.create_task(
send_results_realtime()
)
await websocket.send_json({
"type": "status",
"message": "recognition_started"
})
elif msg.get("type") == "stop":
break
except json.JSONDecodeError:
pass
bytes_data = data.get('bytes')
if bytes_data:
client.add_audio(bytes_data)
if (not recognition_started and
len(client.audio_buffer) >= 16000):
client.start_recognition()
recognition_started = True
result_task = asyncio.create_task(
send_results_realtime()
)
await websocket.send_json({
"type": "status",
"message": "recognition_started"
})
elif msg_type == 'websocket.disconnect':
break
except asyncio.TimeoutError:
continue
except WebSocketDisconnect:
break
if result_task:
try:
await asyncio.wait_for(result_task, timeout=35.0)
except asyncio.TimeoutError:
result_task.cancel()
except Exception as e:
logger.error(f"语音识别错误: {e}")
finally:
if result_task:
result_task.cancel()
client.stop()
try:
await websocket.close()
except:
pass
|
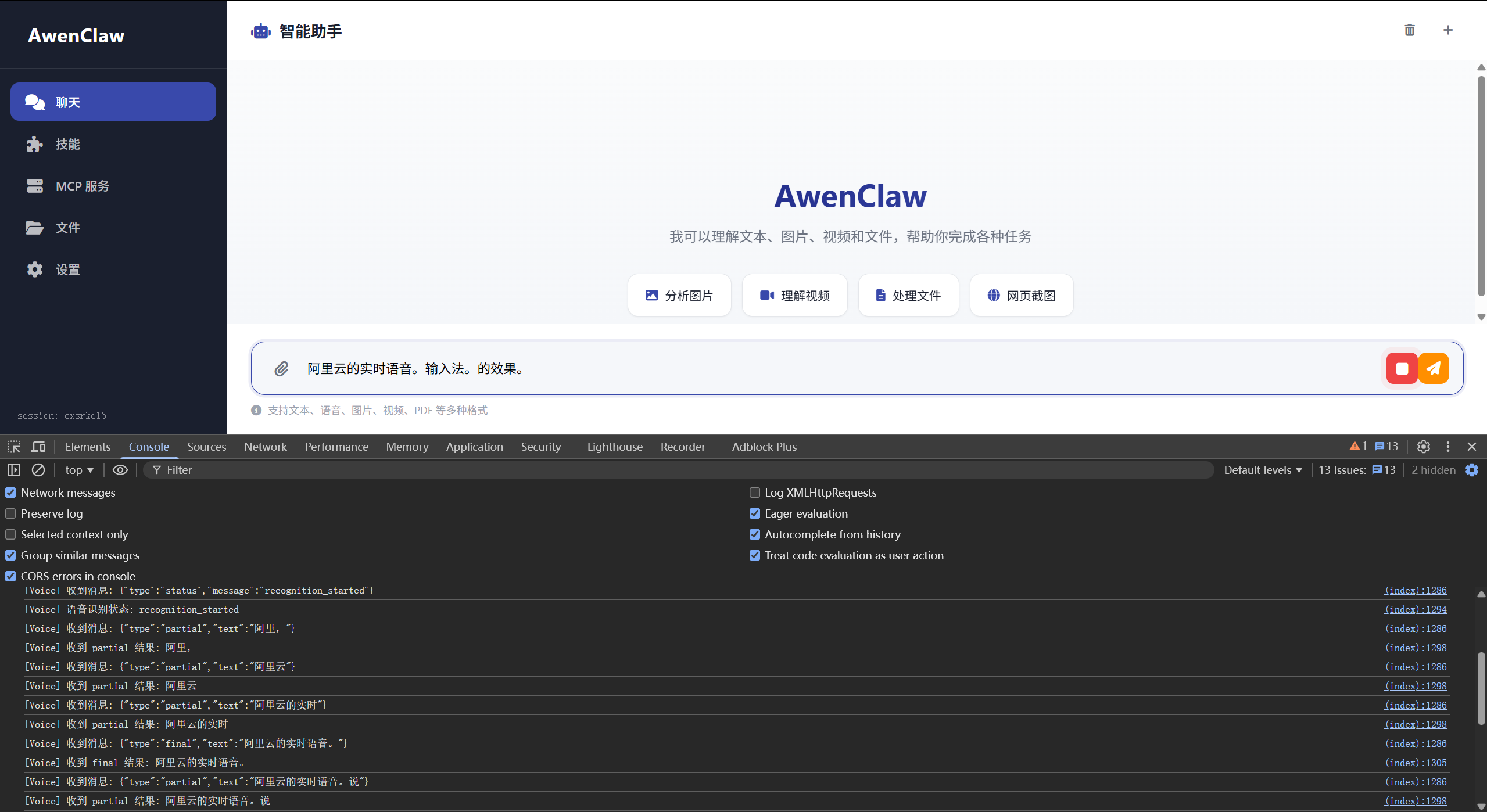
评论
0 条评论