Python 爬取网站图片,我们打开
http://desk.zol.com.cn/bizhi/6429_79089_2.html
发现该网页有很多图片,并且我们点击下一页后会跳转到下一页,那么我们用 python 要如何爬去改页面的图片资源呢?
python requests 库
requests 库的官网http://docs.python-requests.org/en/master/
|
|
安装
|
使用
使用 requests 库,需要对 http 协议有一定的了解,比如状态码,请求头,响应头,方法、字段、参数等概念有一定的了解。
我们导入库后,发送一个 get 请求
|
上面的 requests.get(url,params=None,**kwargs) 中:
url: 是指获取页面的 url 连接
params:是 url 的额外参数,比如一些请求头,例如有些网站做了防盗链,需要特殊的 referer 或 user-agent 才可以访问,否则拒绝访问,那么我们可以通过定制一些请求头去进行访问。
**kewrgs 12个控制访问的参数
通过 r.headers 可以获取响应头信息
|
response 对象的属性
|
| 属性 | 说明 |
|---|---|
| r.status_code | HTTP请求的返回状态,200表示成功,其他都表示有问题 |
| r.text | HTTP 响应内容的字符串形式,url 对应的页面内容 |
| r.encoding | HTTP Header 中猜测的响应头状态码 |
| r.apparent_encoding | 从内容中分析出的响应内容编码方式 |
| r.content | 响应内容的二进制形式 |
|
|
如果乱码,则
|
如果 header 中不存在 charset,则认为编码为 ISO-8859-1
请求异常处理
| 属性 | 说明 |
|---|---|
| requests.ConnectionError | 网络连接错误异常,如 DNS 查询失败, 拒绝连接 |
| requests.HTTPError | HTTP 错误异常 |
| requests. URLRequired | URL 缺失异常 |
| requests.TooManyRedirects | 连接远程服务器超时 |
| requests.Timeout | 请求 URL 超时,产生的异常 |
|
requests 的 http 方法
| 方法 | 说明 |
|---|---|
| requests.requets() | 构造一个请求,支持以下各自方法的基础 |
| requests.get() | get请求,获取实体内容 |
| requests.head() | 获取头信息 |
| requests.post() | 提交 POST 请求 |
| requests.put() | 提交 PUT 请求 |
| requests.patch() | 提交局部的修改请求 |
| requests.delete() | 提交删除请求 |
我们使用爬虫,大部分都是使用get方法比较多。
Beautiful Soup
安装
|
官网
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
使用
|
导入bs4
|
显示title
|
打印a标签
|
上面的只能返回第一个标签
##获取名字
|
获得数据内容
|
查看标签类型
|
获得标签中的内容
|
上面我们看到p标签的内容中其实是包含一个b的
|
说明该方法是可以跨域多个层的
beautiful soup元素

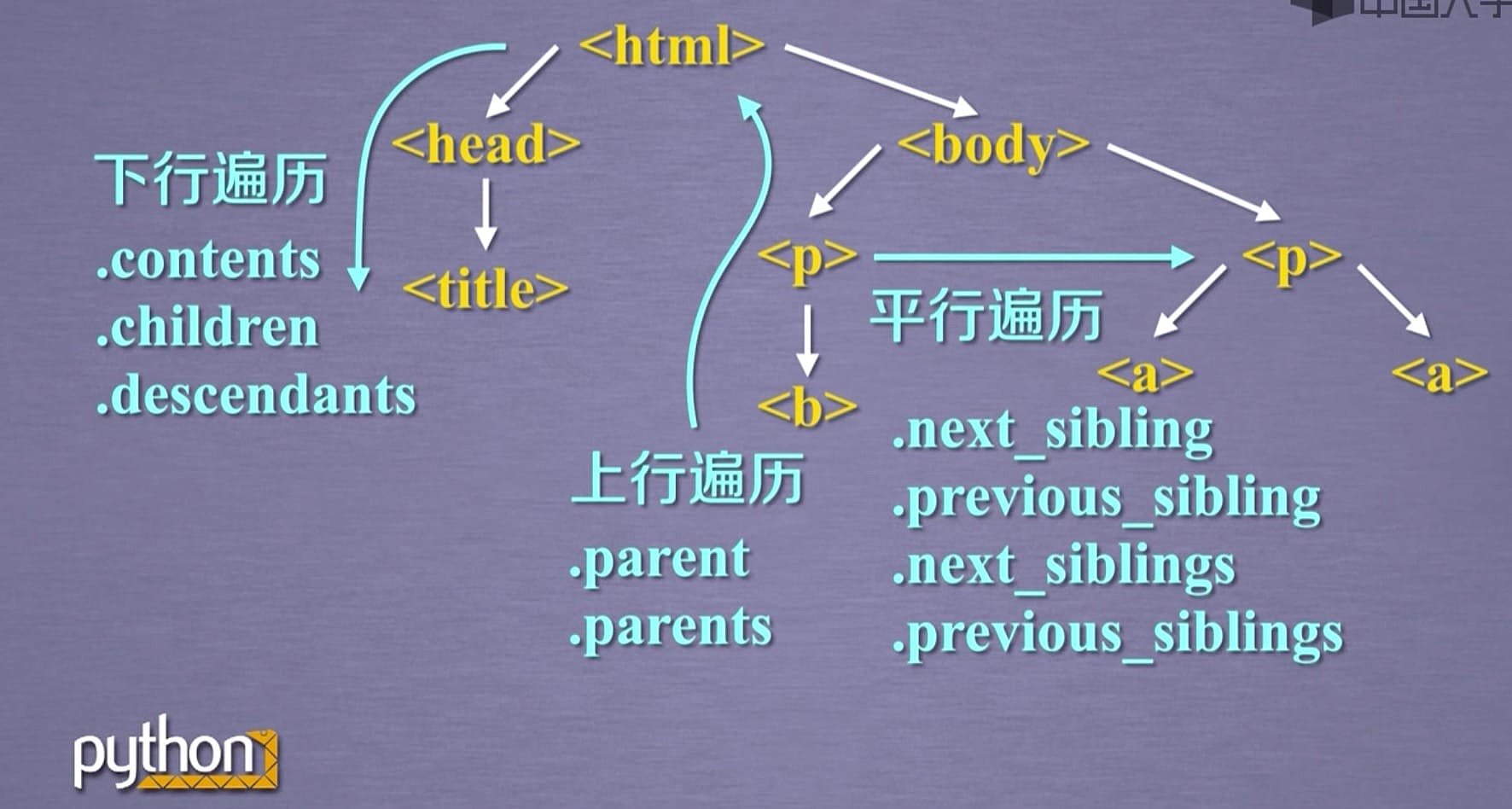
遍历
遍历分上下平行遍历
|
方法
- .contents
- .children .desendants 需要配合for语句使用
上行遍历
|
标签书上行遍历

方法
- .parent
- .parents
平行遍历

获取下一个标签
|
|
获取前一个阶段
|
方法
- .next_sibling
- .previous_sibling
- .next_siblings
- .previous_siblings
更友好的显示内容
|
#bs4 库的基本元素
- tag 标签
- name 名字
- -attributes 标签属性
- navigablestring 标签之间的字符串
- comment 注释
本文内容来自网易云课堂
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 阿文的博客!
评论
0 条评论