一、为什么需要外部知识库 Dify 内置的知识库功能很好用,但有一个前提:你得把数据上传到 Dify 的服务器。对于已经有海量文档存储在阿里云 OSS 上的场景(比如我的博客文章、公司内部的文档库),重复上传既不优雅也不现实。
Dify 外部知识库 API 提供了一个完美的解决方案:Dify 只负责发送检索请求,真正的知识库由你自己的服务维护。
用户提问 → Dify → 你的外部知识库服务 → 返回相关文档 → Dify 传给 LLM
二、两种检索方案的对比 在接入向量检索之前,我先用关键词匹配做了一个版本。对比之后,差距非常明显:
检索方式
查询”外婆”的返回结果
原理
关键词匹配
《聊一聊劫持.md》
“外”和”婆”作为单字分别匹配
向量检索
《我的外婆,从不内耗.md》
语义理解”外婆”的概念
关键词匹配的问题在于:中文的单字匹配太容易误中。几乎所有文章都包含”外”或”婆”这两个字,导致搜索结果毫无意义。而向量检索基于语义相似度,能真正理解用户的查询意图。
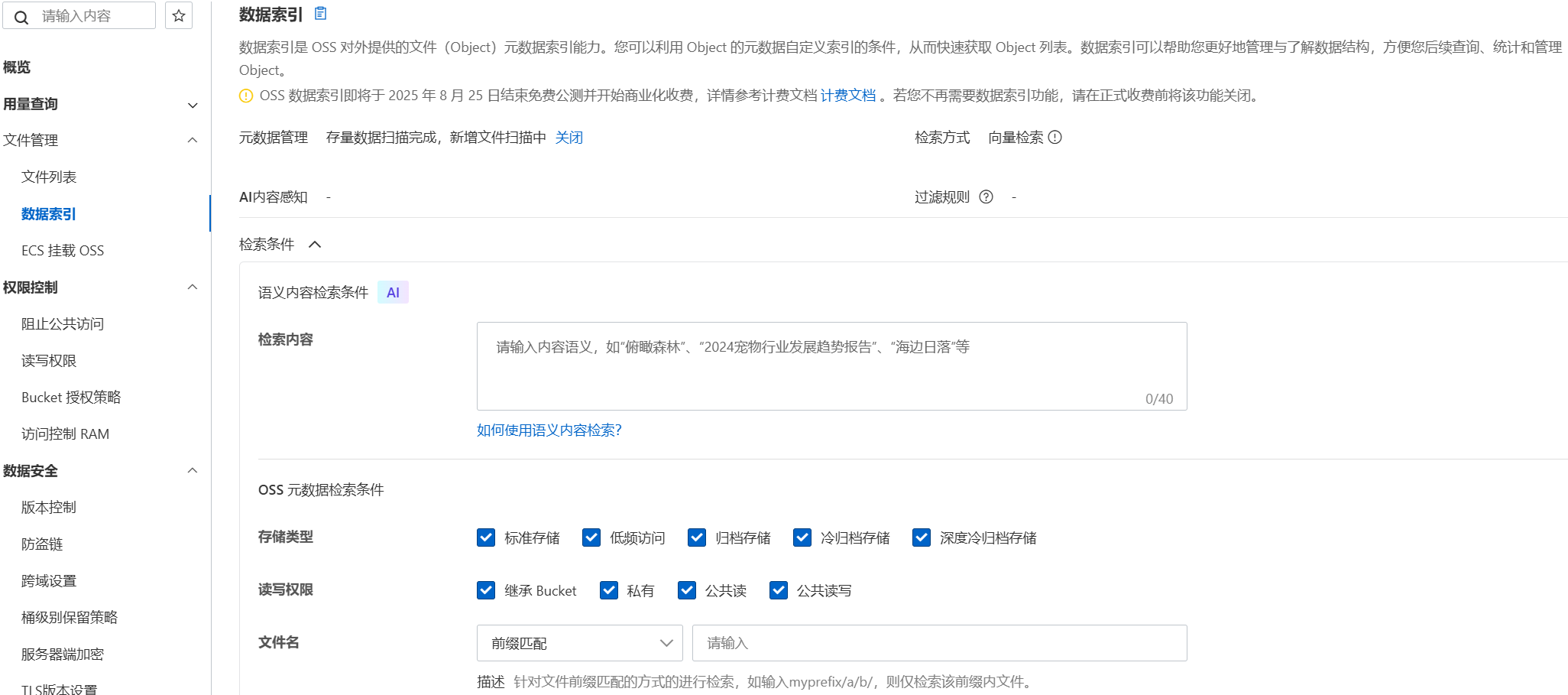
三、阿里云 OSS 向量检索 阿里云 OSS 在 2024 年推出了向量检索 功能,核心能力包括:
自动向量化 :开启功能后,OSS 会自动提取文本、图片、音视频的内容特征,生成向量索引语义检索 :支持自然语言描述检索,如”外婆”、”雪天户外监控”、”2024 年经营分析”多模态支持 :文本、图片、音频、视频统一检索地域覆盖 :杭州、上海、北京、深圳等主流地域均已支持
配置标签
开启方式 在 OSS 控制台 → 数据索引 → 选择”向量检索”模式即可开启。开启后系统会自动扫描存量文件并构建索引,200 个 Markdown 文件大约几分钟就能就绪。
注意 :向量检索会产生 API 调用费用,建议根据实际文件量评估成本。
四、项目架构 我的项目基于 Go + Gin 框架,整体架构如下:
Dify 请求v1 /external-kb/retrievalOSS SDK V2 OSS SDK V1
这里用到了两个阿里云 OSS SDK:
V1 (aliyun-oss-go-sdk):负责文件的上传、下载、列表等基础操作V2 (alibabacloud-oss-go-sdk-v2):支持向量检索等新特性
五、核心代码实现 5.1 向量检索服务封装 type OSSVectorService struct {string string func (s *OSSVectorService) string , topK int64 , mediaType string ) ([]OSSVectorResult, error ) {"semantic" ), if mediaType != "" {string {mediaType},
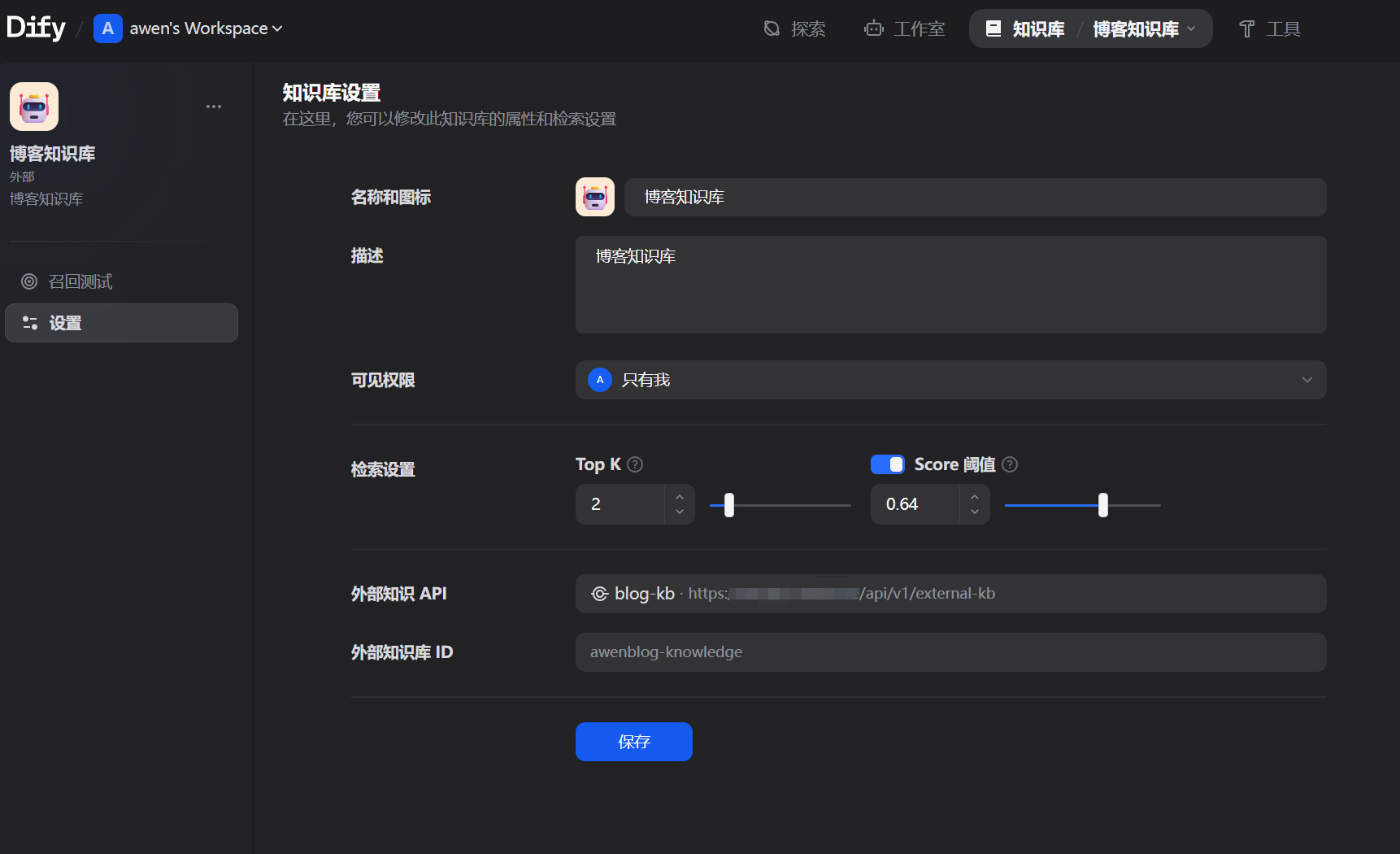
5.2 Dify API 规范对接 Dify 外部知识库要求实现一个标准的检索接口:
请求 :
{ "knowledge_id" : "awenblog-12" , "query" : "外婆" , "retrieval_setting" : { "top_k" : 5 , "score_threshold" : 0.1 } }
响应 :
{ "records" : [ { "content" : "《我的外婆,从不内耗》读书笔记..." , "score" : 0.9 , "title" : "posts/2026/04/我的外婆从不内耗.md" , "metadata" : { "path" : "posts/2026/04/我的外婆从不内耗.md" , "url" : "https://file.awen.me/..." } } ] }
Handler 的核心逻辑:
func (h *ExternalKnowledgeHandler) if h.cfg.SearchMode == "semantic" {else {
5.3 跨 Bucket、跨地域访问 我的博客文章存在杭州区域的 awenblog bucket,而项目原有配置连接的是上海区域的 file201503。这里需要动态创建对应 region 的 OSS Client:
func (s *OSSService) string ) (*oss.Bucket, error ) {if region == "" || region == s.config.Region {return s.client.Bucket(bucketName)return client.Bucket(bucketName)
六、踩坑记录 坑 1:GOMODCACHE 权限问题 本地编译时报错 mkdir /usr/local/gopath: permission denied。解决方法是设置用户可写的 GOPATH:
export GOPATH=/home/wenjun/gopathexport GOMODCACHE=/home/wenjun/gopath/pkg/mod
坑 2:CGO 与 GLIBC 版本不兼容 直接 go build 编译的二进制在服务器上运行时报错 GLIBC_2.34 not found。必须用静态编译:
CGO_ENABLED=0 go build -ldflags='-s -w' -o bin/blog-api cmd/main.go
坑 3:Endpoint 与 Region 不匹配 awenblog 在杭州区域,但原有 Client 连接的是上海。未正确配置 EXTERNAL_KB_REGION 时,会报 AccessDenied: The bucket you are attempting to access must be addressed using the specified endpoint.
坑 4:Nginx 504 超时 串行下载 200 篇文章做关键词匹配,耗时超过 Nginx 的默认超时时间。解决方法是使用 goroutine 并发处理:
const maxWorkers = 15 make (chan string , len (files))make (chan result, len (files))for i := 0 ; i < maxWorkers; i++ {go func () for file := range fileCh {
并发优化后,响应时间从数秒降到了 0.2 秒。
坑 5:空数组 vs null Dify 要求没有匹配结果时返回 {"records": []},但 Go 的 nil slice 在 JSON 序列化后会变成 null。需要在返回前做兜底处理:
if records == nil {
七、配置速查 true
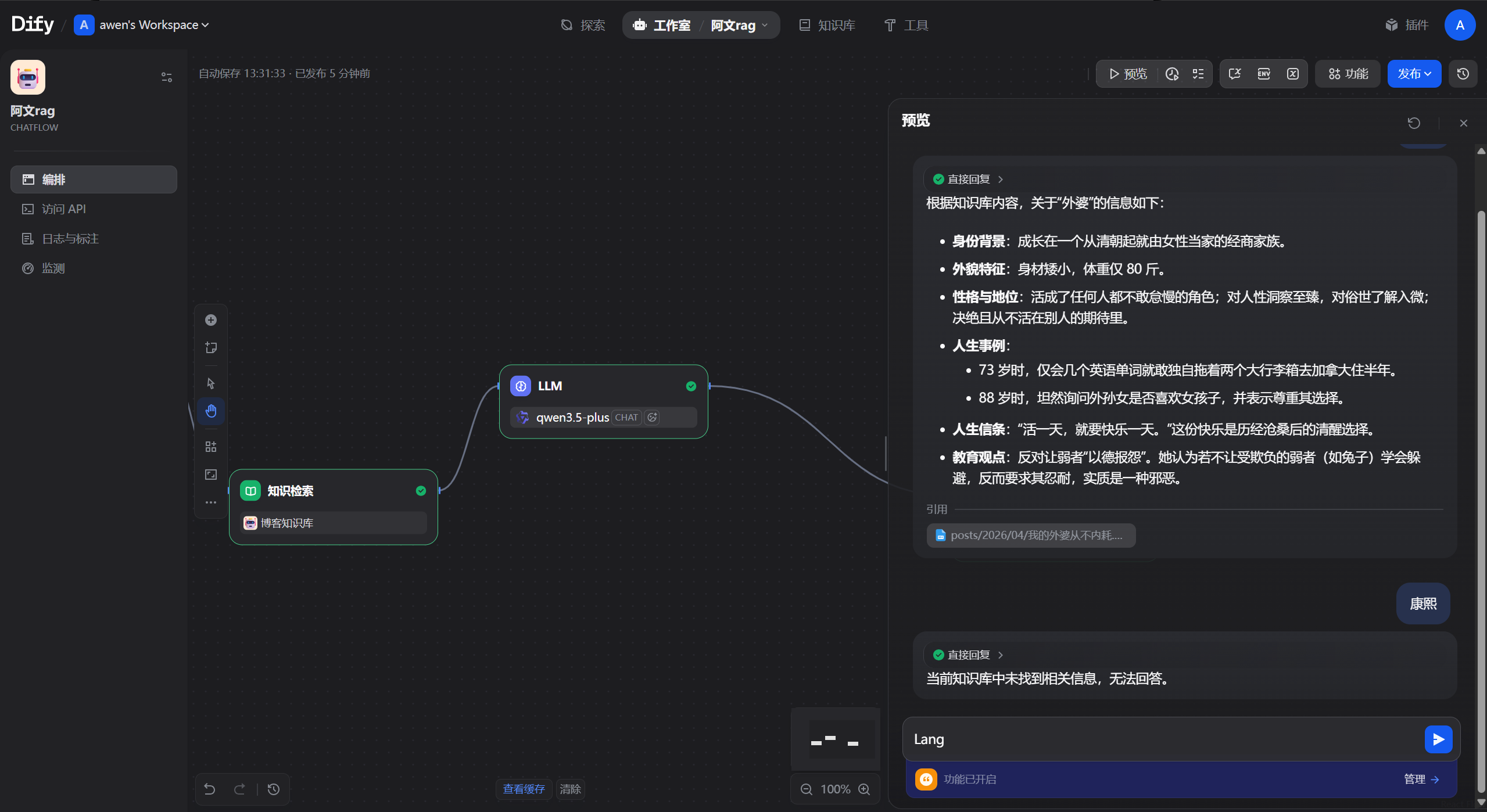
八、效果展示 用 Postman 测试语义检索:
curl -X POST https://api.api.com/api/v1/external-kb/retrieval \"Authorization: Bearer sk-2esfdg3" \"Content-Type: application/json" \'{ "knowledge_id": "awenblog-12", "query": "外婆", "retrieval_setting": {"top_k": 5, "score_threshold": 0.1} }'
返回结果:
{ "records" : [ { "content" : "《我的外婆,从不内耗》读书笔记..." , "score" : 0.9 , "title" : "posts/2026/04/我的外婆从不内耗.md" , "metadata" : { "path" : "posts/2026/04/我的外婆从不内耗.md" , "url" : "https://xxx/..." } } ] }
再试试搜”Docker”、”读书笔记”、”内耗”——都能返回语义相关的结果,而不是字面硬匹配。
九、写在最后 从关键词匹配到向量检索,不只是技术方案的升级,更是从”字符串游戏”到”语义理解”的跨越。当你的知识库里有几百篇、几千篇文章时,用户不会记得每篇文章的标题和关键词,他们只会用自然语言提问。向量检索让”搜得到”变成了”搜得对”。
阿里云 OSS 向量检索的优势在于零运维 :不需要自己搭建向量数据库,不需要写 embedding 代码,不需要处理向量索引的更新——OSS 帮你做了所有的事情。对于已经重度使用 OSS 存储文档的场景,这是成本最低、效果最好的 RAG 方案之一。
完整代码已开源在 blog_api 项目中,欢迎参考和讨论。
评论
0 条评论