又拍云提示了日志分析和日志下载功能,通过后台可以根据需求查询访问最多的 IP 或 URL,以此设置一些策略,达到限制重复 IP 访问的效果
后台功能简介
后台点击工具箱–日志管理
可以看到全网加速和直播加速日志,切换到日志分析,可以选择对应的服务名和域名,然后按类型进行划分并且选择日志进行查询
- 热门引用页面
- 热门文件
- 热门客户端
- 热门 IP
- 文件大小
- 资源状态
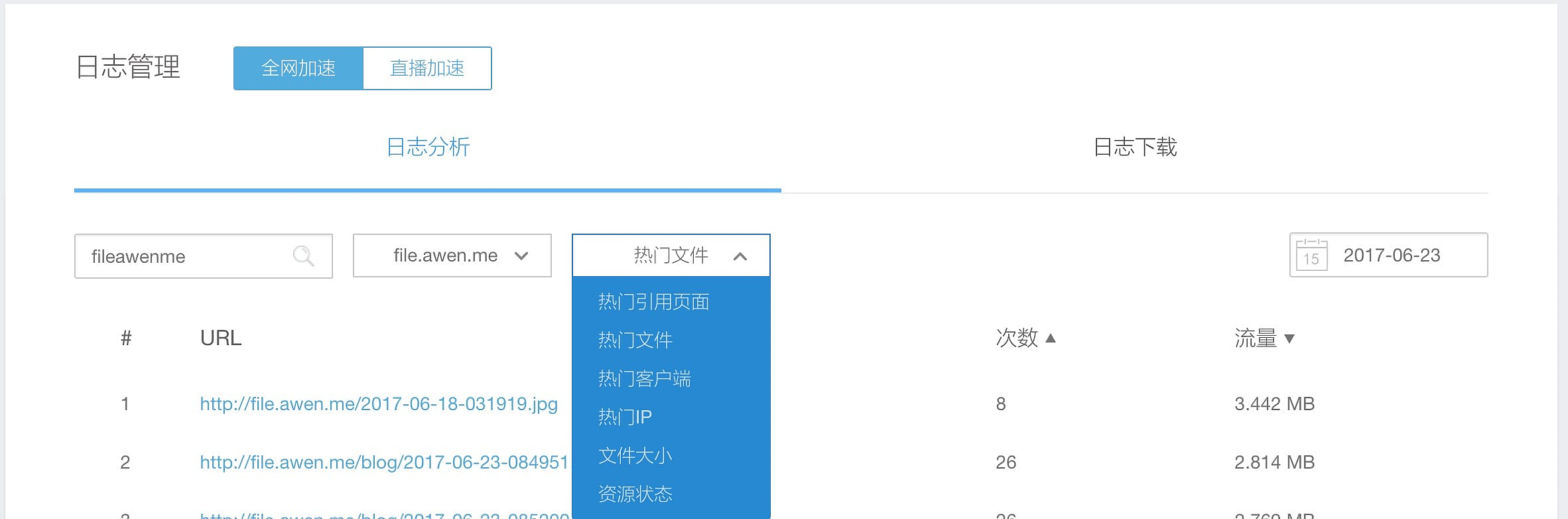
比如,我们希望看下2017-06-23哪个 IP 访问次数最多。可以选择热门 IP 进行查询。如果同一个 IP 请求特别多,可以在防盗链中将对于的Ip 进行限制或者加入黑名单
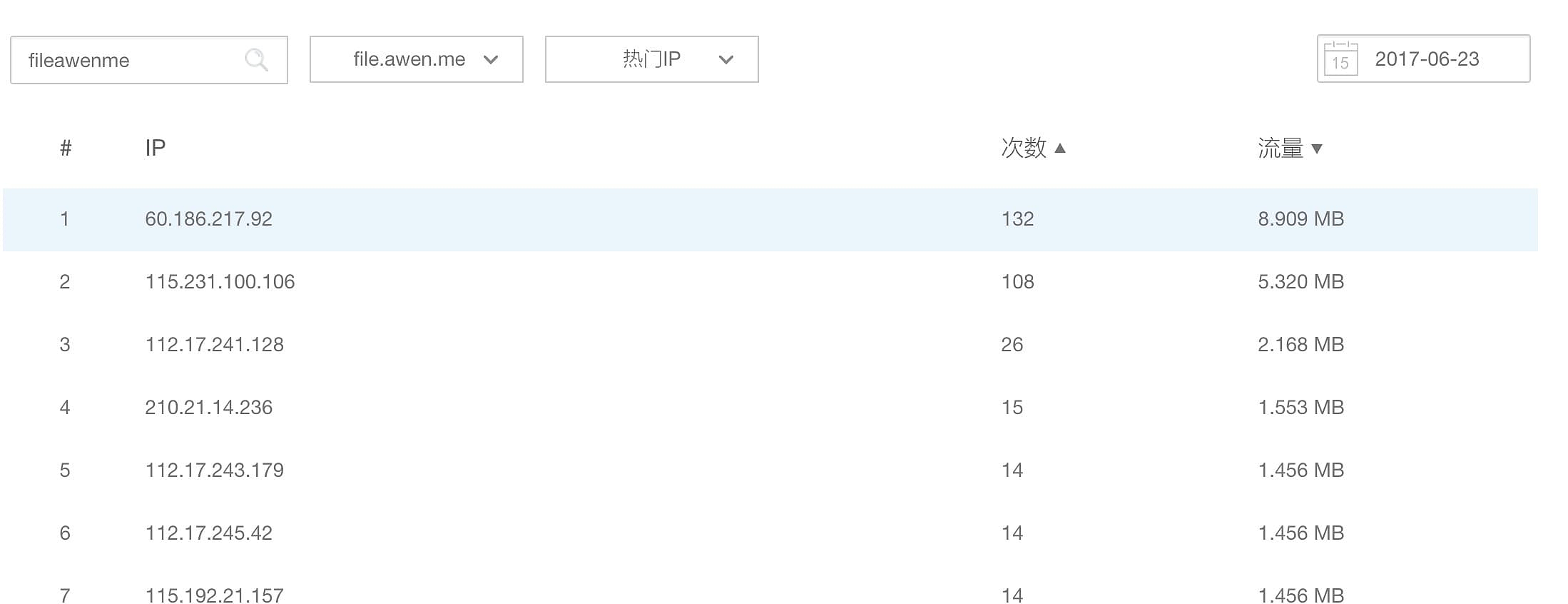
此外,还可以下载日志到本地进行分析,又拍云的日志是一小时一出,比如1点到2点之间的日志,会在2点半左右更新在后台。

下载日志
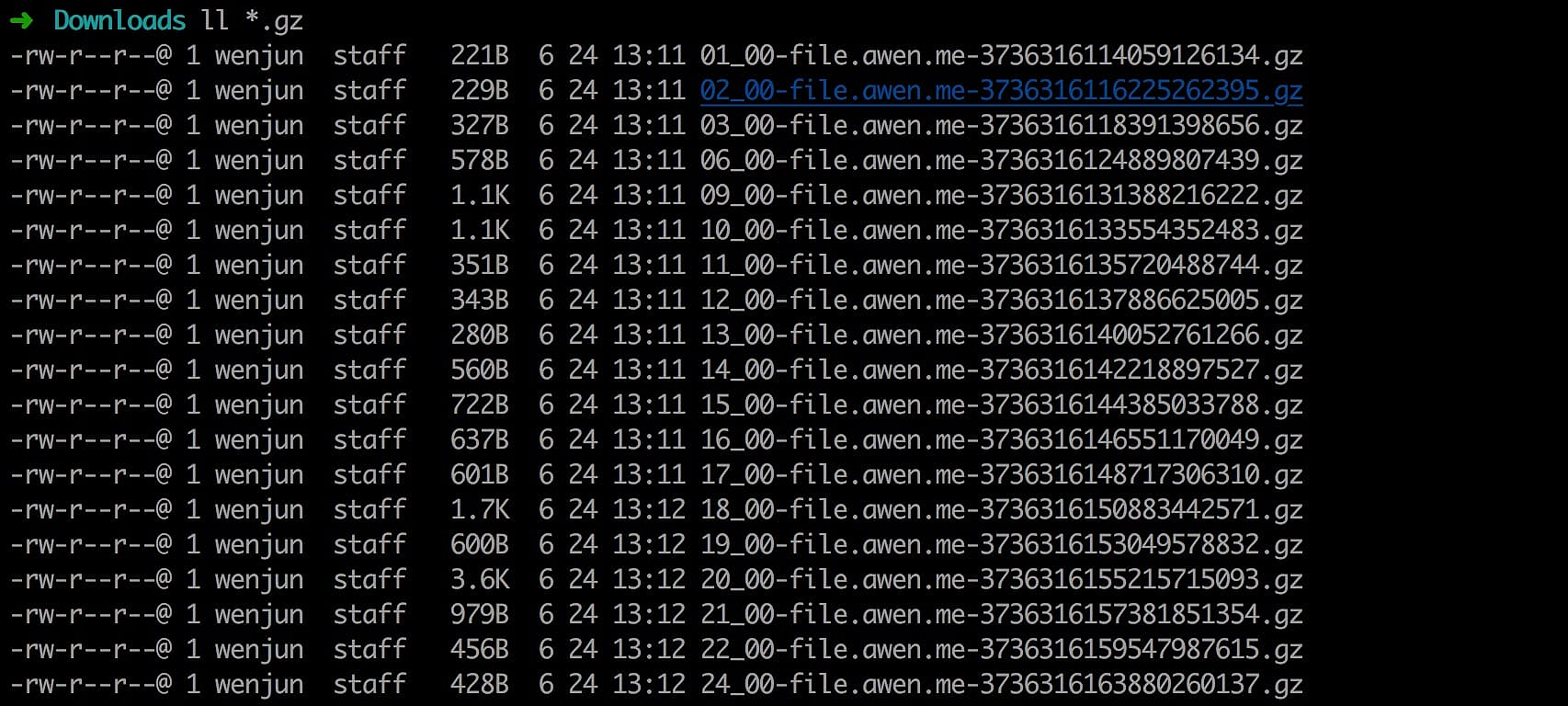
比如我们将23号一天的日志全部下载到本地,然后将日志文件合并为一个文件
➜ Downloads cat *.gz >> awen.gz
➜ Downloads ll awen.gz
-rw-r--r-- 1 wenjun staff 15K 6 24 13:26 awen.gz然后解压
➜ Downloads gunzip awen.gz
➜ Downloads ll awen
-rw-r--r-- 1 wenjun staff 170K 6 24 13:26 awen然后查看日志
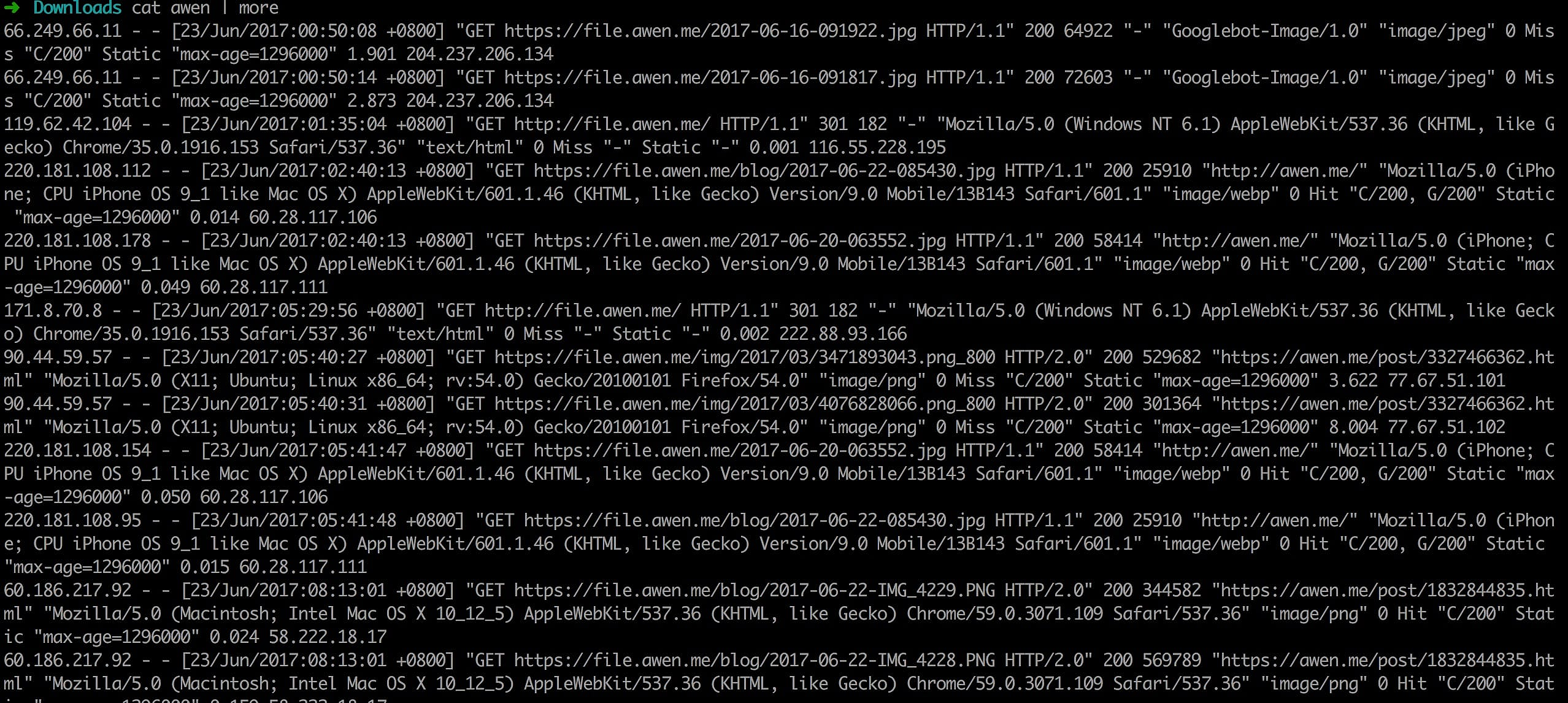
日志字段含义
66.249.66.11 - - [23/Jun/2017:00:50:08 +0800] "GET https://file.awen.me/2017-06-16-091922.jpg!awen) HTTP/1.1" 200 64922 "-" "Googlebot-Image/1.0" "image/jpeg" 0 Miss "C/200" Static "max-age=1296000" 1.901 204.237.206.134从左到右分别是
- 客户端 IP: 66.249.66.11
- 空
- 空
- 请求时间: [23/Jun/2017:00:50:08 +0800]
- 请求方法: GET
- 请求的 URL:https://file.awen.me/2017-06-16-091922.jpg!awen)
- 状态码:200
- 请求的字节:64922
- User-agent:Googlebot-Image/1.0”
- 文件类型:”image/jpeg”
- 0 0 表示客户端向服务器发起请求的内容大小
- 是否缓存命中 CDN Miss 表示未命中
- C/200 表示回源站响应200,如果是 U/200 则表示又拍云存储类型,如果你是自主源站,显示为 U,则是开启了镜像功能,文件被存储在 CDN
- Static 表示静态请求
- “max-age=1296000” 缓存控制头信息
- 节点请求耗时:1.901
- CDN 节点:204.237.206.134
日志格式
$remote_addr - $remote_user [$time_local] "$request_method $scheme://$http_host$uri$querystring $server_protocol" $status $body_bytes_sent "$http_referer" "$http_user_agent" $content_type $request_content_length $cache_hit $source_code $is_dynamic $cache_control $request_time $edge_server_ip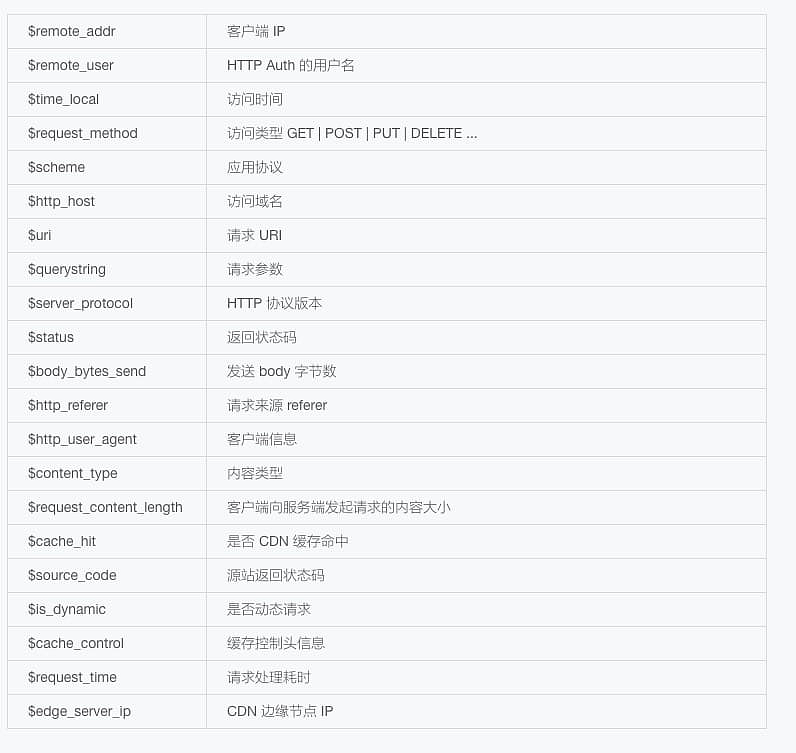
过滤日志
通常过滤日志可以使用 awk sed grep 进行处理
比如说我们希望看看哪个 IP 访问的最多,判断下和又拍云后台统计的 IP 对不对得上,可以按照如下步骤操作
1.过滤日志的第一列,对 IP 进行排序统计
➜ Downloads cat awen | awk '{print $1}' | sort| uniq -c |sort -r
132 60.186.217.92
108 115.231.100.106
26 112.17.241.128
20 116.237.32.67
14 14.24.209.40
14 115.192.21.157
14 112.17.245.42
14 101.226.79.182
12 49.5.0.66
11 153.37.114.107
8 36.23.228.97
7 36.35.35.97
7 202.189.0.2
7 125.121.41.81
7 124.160.213.58
7 117.136.0.254
7 115.206.56.50
7 115.193.173.10
7 112.26.238.72
7 112.10.109.202
7 100.64.126.174
6 61.151.226.202
3 66.249.66.11
3 223.155.233.4
2 90.44.59.57
2 171.8.70.8
1 66.249.66.15
1 42.156.138.103
1 35.187.149.136
1 220.181.108.95
1 220.181.108.178
1 220.181.108.154
1 220.181.108.112
1 202.200.151.142
1 182.138.102.194
1 119.62.42.104
1 112.17.242.187得到如上的结果
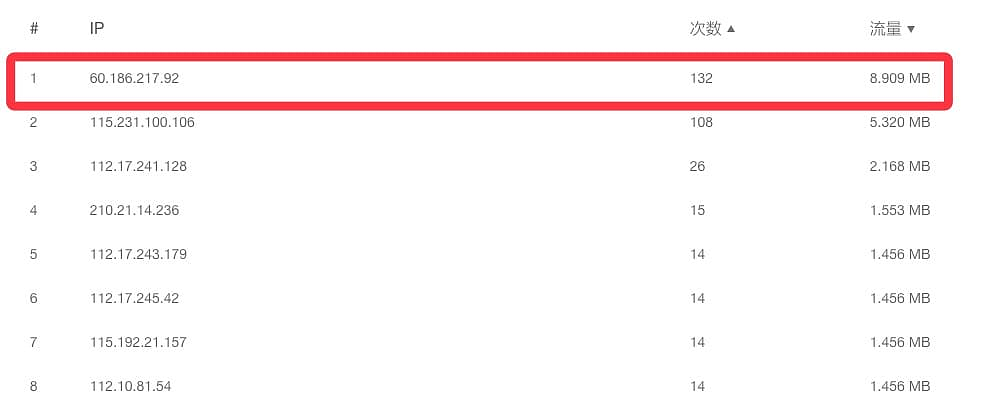
cat awen | awk '{print $1}' | sort| uniq -c |sort -r这个命令的意思是先用 awk 打印$1,awk 默认按空格进行分割,$1表示第一列,然后获取到第一列后 进行排序在统计,uniq只能对相邻的行进行比较。所以要先排序。然后在sort -c 参数进行一次倒序排列得到如上的结果,可以看到60.186.217.92 在23号这天访问了132次。
132 60.186.217.92
108 115.231.100.106我们去后台查下,发现是对上了,就说明统计没有出现错误的。
其实如果日志量大的话,比如超过1G cat 会很耗内存,不如直接 awk 节省资源
awk '{print $1}' | sort| uniq -c |sort -r awen那么如何统计流量呢?从日志看出,这个就稍微复杂点了,我们要对每个 IP 的流量进行统计,就是先要拿到 IP,然后在针对 IP 的请求字节进行统计计算,这里就要用到 awk 的循环和对列的相加了
➜ Downloads cat awen| grep ^60.186.217.92| awk 'BEGIN{total=0}{total+=$10/1024/1024}END{print total}'
8.90929上面是针对 60.186.217.92 的这个IP 进行统计,对比下后台,计算结果也是没有错的
如果要统计所有的流量
➜ Downloads awk 'BEGIN{total=0}{total+=$10/1024/1024}END{print total}' awen
29.2603发现一天的流量是20M,不过又拍云的计费是按地区和文件类型来计算的。比如国内和海外的计费价格是不一样的,动态和静态请求的计费也是不一样的。
其他的自行研究

