本文介绍如何使用 LangGraph 构建一个具备自动 Skill 发现、记忆存储和本地命令执行能力的智能 Agent,并提供了一个简洁的 Web 聊天界面。
项目概述 最近对 AI Agent 技术产生了浓厚兴趣,特别是 LangGraph 这个用于构建有状态 AI 工作流的框架。它相比传统的 LLM 调用,最大的特点是支持循环、持久化和条件分支 ,非常适合构建复杂的智能体系统。
基于 LangGraph,我实现了一个具有以下特性的 Agent 系统:
✅ 文档驱动的 Skill 系统 :每个 Skill 都有详细的 Markdown 文档,AI 根据文档理解技能能力
✅ 智能 Skill 选择 :根据用户输入自动选择最合适的 Skills,而非加载全部工具
✅ Skill 自动发现 :自动加载 skills/ 目录下的功能模块
✅ 记忆存储 :使用 MemorySaver 保存对话状态,支持多会话隔离
✅ 本地命令执行 :通过 CLI Skill 安全执行系统命令(如 dig 域名查询)
✅ 文件操作 :支持读取、写入、列出项目目录下的文件
✅ 麦当劳服务 :基于 FastMCP 的麦当劳点餐助手
✅ 高德地图服务 :集成高德 API,提供地理编码、POI 搜索、路径规划
✅ GPS 定位服务 :自动获取当前位置,支持 IP 定位和坐标解析
✅ 前端技能展示 :聊天界面实时展示调用的技能和工具
✅ FastMCP 集成 :兼容 MCP 协议,可独立运行 MCP 服务器
文档驱动的 Skill 系统 传统的 Agent 系统通常会将所有工具都绑定到 LLM,让 LLM 自己决定调用哪个。这种方式的问题是:
工具过多时性能下降 :LLM 需要处理大量工具描述上下文干扰 :不相关的工具会影响 LLM 的判断难以扩展 :新增工具需要修改核心代码
我采用了类似 OpenClaw 的文档驱动 方案:
系统架构 ┌─────────────────┐ ┌──────────────────┐ ┌─────────────────┐Skill Selector │────▶│ 选择相关 Skills │Skill 文档 │
Skill 文档格式 每个 Skill 都有一个 Markdown 文档,位于 skills/docs/{skill_name}_skill.md:
# CLI Skill - 命令行工具 ## 描述 ## 适用场景 - 查询域名的 IP 地址(A 记录)- 查询域名的 IPv6 地址(AAAA 记录)- 查询域名的邮件服务器(MX 记录)- ...## 工具函数 ### dig_query 查询域名的 DNS 解析记录。 **参数:** | 参数名 | 类型 | 必填 | 说明 | |--------|------|------|------| | domain | string | 是 | 要查询的域名 | | record_ type | string | 否 | DNS 记录类型 |**使用示例:** ```python dig_query(domain="example.com", record_type="A")
class SkillSelector :"""根据用户输入选择最合适的 Skill""" def __init__ (self, skills: List [Skill] ):self .skills = skillsself .skill_docs = self ._build_skill_docs()def select_skills (self, user_input: str ) -> List [str ]:"""根据用户输入选择应该激活的 Skills""" f"""根据用户的输入,判断需要激活哪些技能。 {self.skill_docs} 选择规则: 1. 分析用户的意图和需求 2. 选择最相关的技能(可以选择多个) 3. 如果用户只是闲聊,返回 "none" 4. 只返回技能名称列表,用逗号分隔 输出格式:skill1,skill2 或 none""" f"用户输入: {user_input} " )return selected_skills
工作流程
用户输入 :”查询 example.com 的 A 记录”Skill 选择 :AI 分析后选择 cli skill工具绑定 :只将 cli skill 的工具绑定到 LLM执行调用 :LLM 调用 dig_query 工具结果返回 :展示查询结果
这种方式的优势:
精准匹配 :只加载相关技能,减少干扰可扩展 :新增 skill 只需添加文档和实现透明可控 :可以查看 AI 选择了哪些技能
架构设计 核心组件 agent_web_chat/ / / / /
技术栈
组件
技术
说明
Agent 框架
LangGraph
构建有状态的 AI 工作流
LLM
DeepSeek API
deepseek-chat 模型
Web 框架
FastAPI
高性能异步 Web 框架
模板引擎
Jinja2
HTML 模板渲染
记忆存储
MemorySaver
LangGraph 内置的内存存储
Skill 系统设计 1. Skill 基类 所有 Skill 都继承自统一的基类,遵循约定优于配置的原则:
from abc import ABC, abstractmethodfrom typing import List from langchain_core.tools import BaseToolclass Skill (ABC ):"""Skill 基类,所有 skill 必须继承并实现以下方法""" @property @abstractmethod def name (self ) -> str :"""Skill 名称""" pass @property @abstractmethod def description (self ) -> str :"""Skill 描述""" pass @abstractmethod def get_tools (self ) -> List [BaseTool]:"""返回该 skill 提供的工具列表""" pass
2. 自动发现机制 通过遍历 skills/ 目录,自动导入并注册所有 skill 模块:
def discover_skills () -> List [Skill]:"""自动发现并实例化所有 skill""" for filename in sorted (os.listdir(current_dir)):if filename.endswith("_skill.py" ):3 ]try :f"." + module_name, package=__name__)for name, obj in inspect.getmembers(module):if (and issubclass (obj, Skill)and obj is not Skilland not inspect.isabstract(obj)print (f"[skills] 已加载: {instance.name} " )except Exception as e:print (f"[skills] 加载 {module_name} 失败: {e} " )return skills
这种设计的好处是:新增 skill 只需在 skills/ 目录下创建新的 _skill.py 文件,无需修改其他代码 。
3. CLI Skill - dig 域名查询 第一个实现的 Skill 是 CLI 工具,支持使用系统 dig 命令查询域名解析:
@tool def dig_query (domain: str , record_type: str = "A" ) -> str :""" 使用 dig 命令查询域名的 DNS 解析记录 """ if not shutil.which("dig" ):return "错误:当前系统未安装 dig 命令" "" .join(c for c in domain if c.isalnum() or c in ".-_" )"" .join(c for c in record_type if c.isalnum())try :"dig" , safe_domain, safe_record, "+short" ],True ,True ,15 ,False ,if not output:return f"未查询到 {safe_domain} 的 {safe_record} 记录" return f"dig {safe_domain} {safe_record} 查询结果:\n{output} " except subprocess.TimeoutExpired:return "错误:dig 命令执行超时"
安全考虑 :
对用户输入进行字符白名单过滤,防止命令注入
设置超时时间,避免长时间挂起
使用 +short 参数只返回关键信息,减少输出噪音
4. File Skill - 文件操作 支持安全的本地文件读写操作:
".." , ".." , ".." ))def _sanitize_path (path: str ) -> str :"""将路径限制在 BASE_DIR 内,防止目录遍历""" if not os.path.isabs(path):if not resolved.startswith(BASE_DIR + os.sep) and resolved != BASE_DIR:raise ValueError(f"路径越界: {path} " )return resolved
提供的工具函数:
read_file(path) - 读取文件内容write_file(path, content) - 写入文件list_dir(path) - 列出目录内容
5. McDonald’s Skill - 麦当劳服务(基于 FastMCP) 麦当劳 Skill 展示了如何基于 FastMCP 框架实现第三方 API 集成:
FastMCP 是什么? FastMCP 是 Prefect 开发的 MCP(Model Context Protocol)Python 框架,特点:
🚀 简单易用 :几行代码创建 MCP 服务器
🛠️ 功能丰富 :支持 Tools、Resources、Prompts
🔗 标准兼容 :符合 Anthropic MCP 协议规范
麦当劳 MCP 服务器 from fastmcp import FastMCP"McDonald's China" )@mcp.tool() def find_nearby_restaurants (latitude: float , longitude: float ) -> str :"""查找附近的麦当劳餐厅""" @mcp.tool() def get_menu (category: Optional [str ] = None ) -> str :"""获取麦当劳菜单""" @mcp.resource("mcdonalds://menu/{category}" def get_menu_resource (category: str ) -> str :"""以资源形式暴露菜单""" @mcp.prompt("order_meal" def order_meal_prompt (meal_type: str = "汉堡套餐" ) -> str :"""点餐建议提示词""" return f"请帮我推荐一份{meal_type} ..." if __name__ == "__main__" :"stdio" )
在 Agent 中集成 通过统一的 Skill 基类包装 FastMCP 服务:
class McDonaldsSkill (Skill ):"""麦当劳服务 Skill""" @property def name (self ) -> str :return "mcdonalds" @property def description (self ) -> str :return "麦当劳餐厅查询、菜单浏览、营养计算、促销活动" def get_tools (self ) -> List [BaseTool]:return [
使用示例 示例 1 :查询汉堡菜单
用户: 我想吃麦当劳,看看有什么汉堡 系统: 🤖 正在分析需求... AI: 🍔 汉堡菜单:
示例 2 :计算营养信息
用户 : 巨无霸、薯条(大)、可乐(中)的热量是多少 系统 : 🤖 正在分析需求... → mcdonalds AI : 🍟 巨无霸, 薯条(大), 可乐(中) 的营养信息: 🔥 热量 : 1230 千卡 🥩 蛋白质 : 31 克 🧈 脂肪 : 54 克 🍞 碳水化合物 : 160 克
示例 3 :多 Skill 协同
用户 : 查看当前目录有什么文件,然后推荐附近的麦当劳 系统 : 🤖 正在分析需求... → file, mcdonalds AI : 📁 当前目录包含: - 01_basics - 基础知识相关 - 02_memory - 内存相关
独立运行 MCP 服务器 麦当劳 MCP 服务器也可以独立运行:
Claude Desktop 配置:
{ "mcpServers" : { "mcdonalds" : { "command" : "python" , "args" : [ "/path/to/mcdonalds_mcp_server.py" ] } } }
完整代码实现 - 麦当劳服务 基于 FastMCP 实现的麦当劳服务 Skill,展示如何集成第三方 API:
class McDonaldsSkill (Skill ):"""麦当劳服务 Skill""" @property def name (self ) -> str :return "mcdonalds" @property def description (self ) -> str :return "麦当劳餐厅查询、菜单浏览、订单服务" def get_tools (self ) -> List [BaseTool]:return [
使用示例 :
用户: 我想吃麦当劳,看看有什么汉堡 系统: 🤖 选择 skills: ['mcdonalds'] AI: 麦当劳有以下汉堡:巨无霸(¥25.5)、麦辣鸡腿汉堡(¥22.0)...
多 Skill 协同示例 :
用户: 查看当前目录有什么文件,然后推荐附近的麦当劳'file' , 'mcdonalds' ]AI : 当前目录有... 要查找麦当劳,需要您提供位置信息...
6. Gaode Skill - 高德地图服务 集成高德地图 API,提供专业的地图和 LBS 服务:
工具
功能
示例
geocode地理编码
地址转坐标
regeocode逆地理编码
坐标转地址
search_poiPOI 搜索
搜索附近地点
route_planning路径规划
驾车/步行/公交路线
get_weather天气查询
城市天气预报
get_district_info行政区划
省市区县查询
使用示例 :
用户: 北京天安门到首都机场怎么走 系统: 🤖 选择 skills: ['gaode'] AI: 🗺️ 驾车路线规划:距离 28.5 公里,预计时间 45 分钟...
7. Location Skill - GPS 定位服务 自动获取设备位置,支持多种定位方式:
工具
功能
说明
get_current_location获取当前位置
IP 定位 + GPS
get_location_by_ipIP 定位
基于网络位置
get_gps_coordinatesGPS 坐标
设备 GPS 获取
parse_address_from_coords坐标解析
经纬度转地址
使用场景 - 当用户说”附近”但没有提供位置时:
用户 : 附近有什么麦当劳餐厅 系统 : 🤖 选择 skills: ['location', 'gaode', 'mcdonalds'] → location : 获取当前坐标 121.4737,31.2304(上海) → gaode : 搜索附近麦当劳 → mcdonalds : 返回餐厅信息 AI : 📍 已获取您的位置:上海市
完整代码实现 以下是各个 Skill 文件的完整代码:
skills/base.py - Skill 基类定义""" Skill 基类定义 """ from abc import ABC, abstractmethodfrom typing import List from langchain_core.tools import BaseToolclass Skill (ABC ):"""Skill 基类,所有 skill 必须继承并实现以下方法""" @property @abstractmethod def name (self ) -> str :"""Skill 名称""" pass @property @abstractmethod def description (self ) -> str :"""Skill 描述""" pass @abstractmethod def get_tools (self ) -> List [BaseTool]:"""返回该 skill 提供的工具列表""" pass
skills/__init__.py - 自动发现与注册""" Skill 自动发现与注册 自动加载 skills 目录下所有以 _skill.py 结尾的模块 """ import osimport importlibimport inspectfrom typing import List from langchain_core.tools import BaseToolfrom .base import Skilldef discover_skills () -> List [Skill]:"""自动发现并实例化所有 skill""" for filename in sorted (os.listdir(current_dir)):if filename.endswith("_skill.py" ):3 ]try :f"." + module_name, package=__name__)for name, obj in inspect.getmembers(module):if (and issubclass (obj, Skill)and obj is not Skilland not inspect.isabstract(obj)print (f"[skills] 已加载: {instance.name} " )except Exception as e:print (f"[skills] 加载 {module_name} 失败: {e} " )return skillsdef get_all_tools () -> List [BaseTool]:"""获取所有 skill 提供的 tools""" for skill in discover_skills():return tools
skills/cli_skill.py - CLI 命令工具""" CLI Skill - 支持执行安全的本地命令 目前支持 dig 查询域名解析 """ import subprocessimport shutilfrom typing import List from langchain_core.tools import tool, BaseToolfrom .base import Skillclass CliSkill (Skill ):"""命令行工具 Skill""" @property def name (self ) -> str :return "cli" @property def description (self ) -> str :return "执行安全的本地命令行工具,如 dig 查询域名解析" def get_tools (self ) -> List [BaseTool]:return [dig_query]@tool def dig_query (domain: str , record_type: str = "A" ) -> str :""" 使用 dig 命令查询域名的 DNS 解析记录 Args: domain: 要查询的域名,例如 "example.com" record_type: DNS 记录类型,例如 "A", "AAAA", "MX", "NS", "TXT", "CNAME" """ if not shutil.which("dig" ):return "错误:当前系统未安装 dig 命令,请安装 bind-utils 或 dnsutils 包。" "" .join(c for c in domain if c.isalnum() or c in ".-_" )"" .join(c for c in record_type if c.isalnum())if not safe_domain:return "错误:域名格式不合法" try :"dig" , safe_domain, safe_record, "+short" ],True ,True ,15 ,False ,if result.returncode != 0 :return f"dig 执行失败: {result.stderr.strip()} " if not output:return f"未查询到 {safe_domain} 的 {safe_record} 记录(或返回为空)。" return f"dig {safe_domain} {safe_record} 查询结果:\n{output} " except subprocess.TimeoutExpired:return "错误:dig 命令执行超时" except Exception as e:return f"错误:执行 dig 时发生异常: {e} "
skills/file_skill.py - 文件操作工具""" File Skill - 操作本地文件的命令脚本 支持读取、写入、列出目录内容 """ import osfrom typing import List from langchain_core.tools import tool, BaseToolfrom .base import Skill".." , ".." , ".." ))def _sanitize_path (path: str ) -> str :"""将路径限制在 BASE_DIR 内,防止目录遍历""" if not os.path.isabs(path):if not resolved.startswith(BASE_DIR + os.sep) and resolved != BASE_DIR:raise ValueError(f"路径越界: {path} " )return resolvedclass FileSkill (Skill ):"""本地文件操作 Skill""" @property def name (self ) -> str :return "file" @property def description (self ) -> str :return "安全地读取、写入、列出项目目录下的文件" def get_tools (self ) -> List [BaseTool]:return [read_file, write_file, list_dir]@tool def read_file (path: str ) -> str :""" 读取指定路径的文本文件内容 Args: path: 文件路径(相对项目根目录或绝对路径) """ try :if not os.path.isfile(target):return f"错误:文件不存在: {target} " with open (target, "r" , encoding="utf-8" ) as f:return f"【{target} 】内容:\n```\n{content} \n```" except ValueError as e:return f"错误: {e} " except Exception as e:return f"读取文件失败: {e} " @tool def write_file (path: str , content: str ) -> str :""" 将内容写入指定路径的文本文件(覆盖写入) Args: path: 文件路径(相对项目根目录或绝对路径) content: 要写入的文本内容 """ try :True )with open (target, "w" , encoding="utf-8" ) as f:return f"成功写入文件: {target} " except ValueError as e:return f"错误: {e} " except Exception as e:return f"写入文件失败: {e} " @tool def list_dir (path: str = "." ) -> str :""" 列出指定目录下的文件和子目录 Args: path: 目录路径(相对项目根目录或绝对路径),默认为当前目录 """ try :if not os.path.isdir(target):return f"错误:目录不存在: {target} " if not items:return f"目录 {target} 为空" f"📁 {target} 内容:" ]for item in sorted (items):"📂" if os.path.isdir(full) else "📄" f" {prefix} {item} " )return "\n" .join(lines)except ValueError as e:return f"错误: {e} " except Exception as e:return f"列出目录失败: {e} "
LangGraph Agent 实现 状态定义 class AgentState (TypedDict ):list , add_messages]
使用 add_messages 注解可以自动将新消息追加到列表,简化了状态管理。
图结构 builder = StateGraph(AgentState)"chatbot" , chatbot_node)"tools" , ToolNode(tools=tools))"chatbot" )"chatbot" ,"tools" : "tools" , END: END}"tools" , "chatbot" )compile (checkpointer=checkpointer)
执行流程 :
用户输入进入 chatbot 节点
LLM 判断是否需要调用工具
如果需要,通过 tools_condition 路由到 tools 节点
工具执行完成后返回 chatbot 节点
LLM 生成最终回复
多会话支持 通过 thread_id 实现会话隔离:
def run_agent (user_input: str , thread_id: str = "default" ) -> str :"configurable" : {"thread_id" : thread_id}}"messages" : [HumanMessage(content=user_input)]},for msg in reversed (result["messages" ]):if isinstance (msg, AIMessage):return msg.contentreturn "(无回复)"
每个会话有独立的记忆,互不影响。用户可以通过设置不同的 thread_id 来开启新的对话。
Web 聊天界面 - 技能可视化 前端不仅展示对话内容,还实时展示 AI 选择和调用的技能:
界面功能
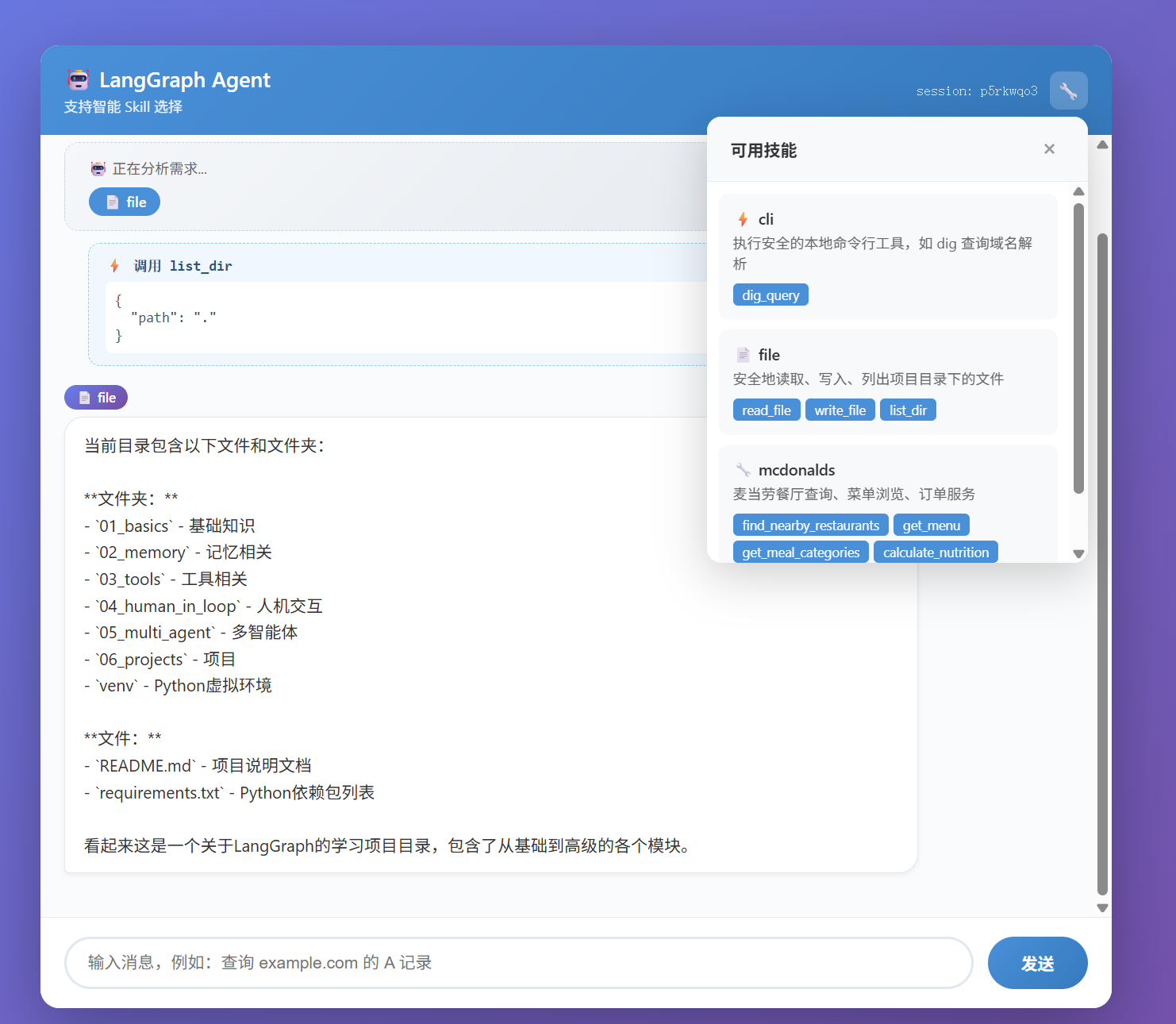
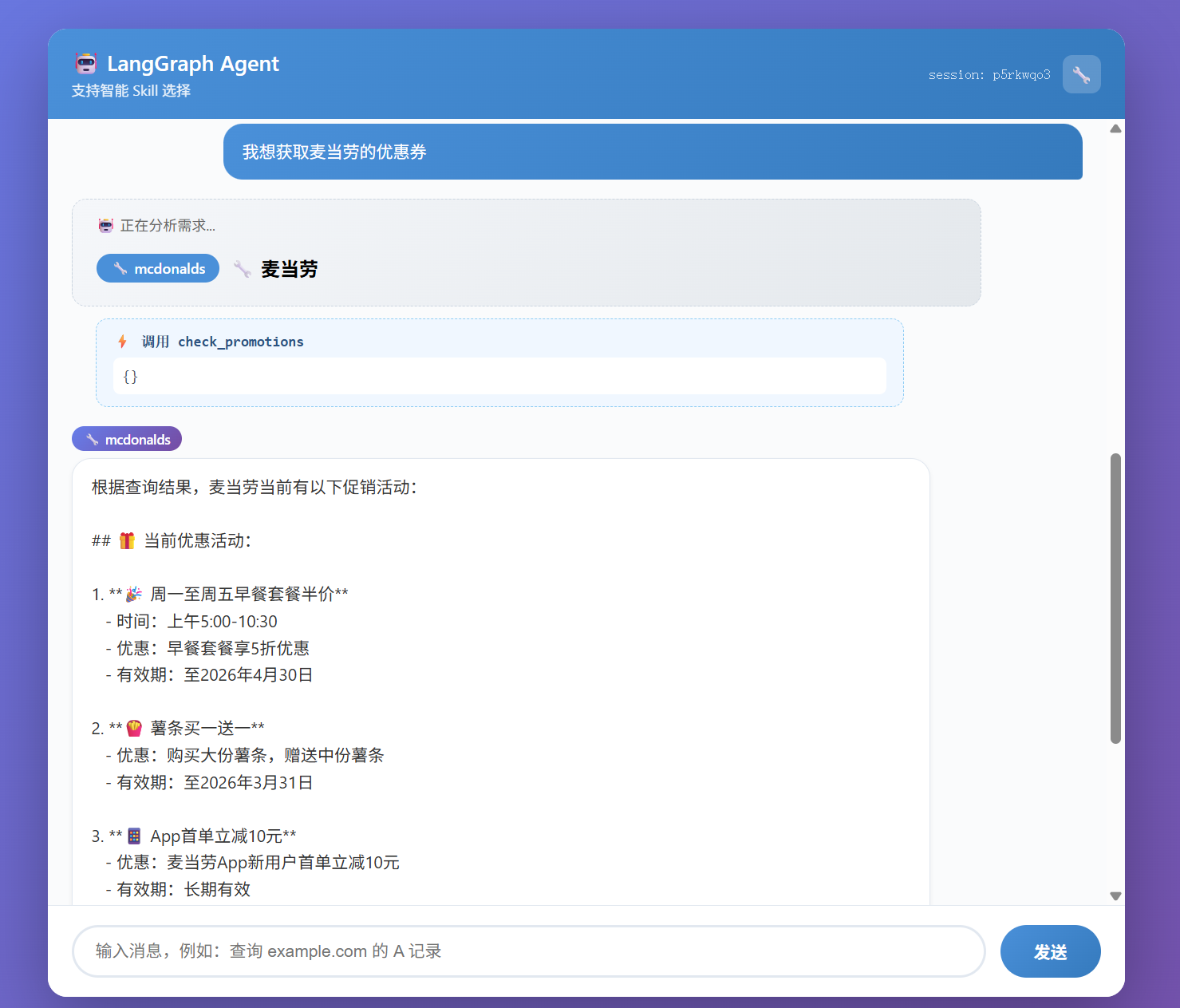
技能面板 :点击 🔧 按钮查看所有可用技能及其文档技能选择展示 :显示 AI 选择了哪些技能来处理请求工具调用展示 :显示具体的工具调用和参数技能标签 :AI 回复旁显示使用的技能标识
界面截图说明 ┌─────────────────────────────────────────┐[🔧] session: abc│"baidu.com" , ...} │[cli] baidu.com 的 A 记录: │1 . 111.63 .65.103 │2 . 124.237 .177.164 │
API 设计 class ChatResponse (BaseModel ):str str List [str ] List [Dict ] @app.post("/chat" , response_model=ChatResponse async def chat (req: ChatRequest ):or str (uuid.uuid4())return ChatResponse("reply" ],"active_skills" , []),"skill_calls" , [])
前端实现 function showSkillSelection (skills ) {const div = document .createElement ('div' );className = 'message skill-selection' ;innerHTML = ` <div class="skill-selection-bubble"> <div class="skill-selection-title">🤖 正在分析需求...</div> <div class="skill-selection-list"> ${skills.map(s => `<span class="selected-skill">${s} </span>` ).join(' → ' )} </div> </div> ` ;appendChild (div);function showToolCall (toolName, args ) {const div = document .createElement ('div' );className = 'message tool-call' ;innerHTML = ` <div class="tool-call-bubble"> <div class="tool-call-title">⚡ 调用 ${toolName} </div> <div class="tool-call-args">${JSON .stringify(args, null , 2 )} </div> </div> ` ;appendChild (div);
使用示例 示例 1:查询域名解析 用户输入 :查一下 example.com 的 A 记录
系统处理 :
Skill 选择 :分析用户意图 → 选择 cli skill工具调用 :调用 dig_query(domain="example.com", record_type="A")结果返回 :
🤖 正在分析需求...cli "domain" : "example.com" , "record_type" : "A" }cli ] 查询结果:. com 的 A 记录有两个 IP 地址:1 . 104.18 .26 .120 2 . 104.18 .27 .120
2. 文件操作 用户 :列出当前目录的文件
Agent :
当前目录包含以下文件和文件夹:- 01_basics - 基础知识相关 - 02_memory - 内存相关 - 03_tools - 工具相关 - 04_human_in_loop - 人机交互相关 - 05_multi_agent - 多智能体相关 - 06_projects - 项目相关 - venv - Python虚拟环境 - README.md - 项目说明文档 - requirements.txt - Python依赖包列表
示例 3:麦当劳点餐助手 用户 :我想吃麦当劳,看看有什么汉堡
系统处理 :
Skill 选择 :分析用户意图 → 选择 mcdonalds skill工具调用 :调用 get_menu(category="burger")结果返回 :
🤖 正在分析需求..."category" : "burger" }25.5 22.0 24.0 21.0 35.0 100
示例 4:营养计算器 用户 :巨无霸、薯条(大)、可乐(中)的热量是多少
系统处理 :
Skill 选择 :分析用户意图 → 选择 mcdonalds skill工具调用 :调用 calculate_nutrition(items=["巨无霸", "薯条(大)", "可乐(中)"])结果返回 :
🤖 正在分析需求..."items" : ["巨无霸" , "薯条(大)" , "可乐(中)" ]}1230 千卡31 克54 克160 克
示例 5:多 Skill 协同 用户 :查看当前目录有什么文件,然后推荐附近的麦当劳
系统处理 :
Skill 选择 :分析复合意图 → 选择 file + mcdonalds skills依次调用 :
调用 list_dir(path=".") 列出文件
调用 find_nearby_restaurants(...) 查找餐厅
🤖 正在分析需求..."path" : "." }01 _basics 02 _memory 03 _tools "latitude" : 31.2304 , "longitude" : 121.4737 }3 家附近麦当劳餐厅:1. 麦当劳上海南京东路餐厅100 号1200 米06 :00 -23 :00 24 小时021 -12345678
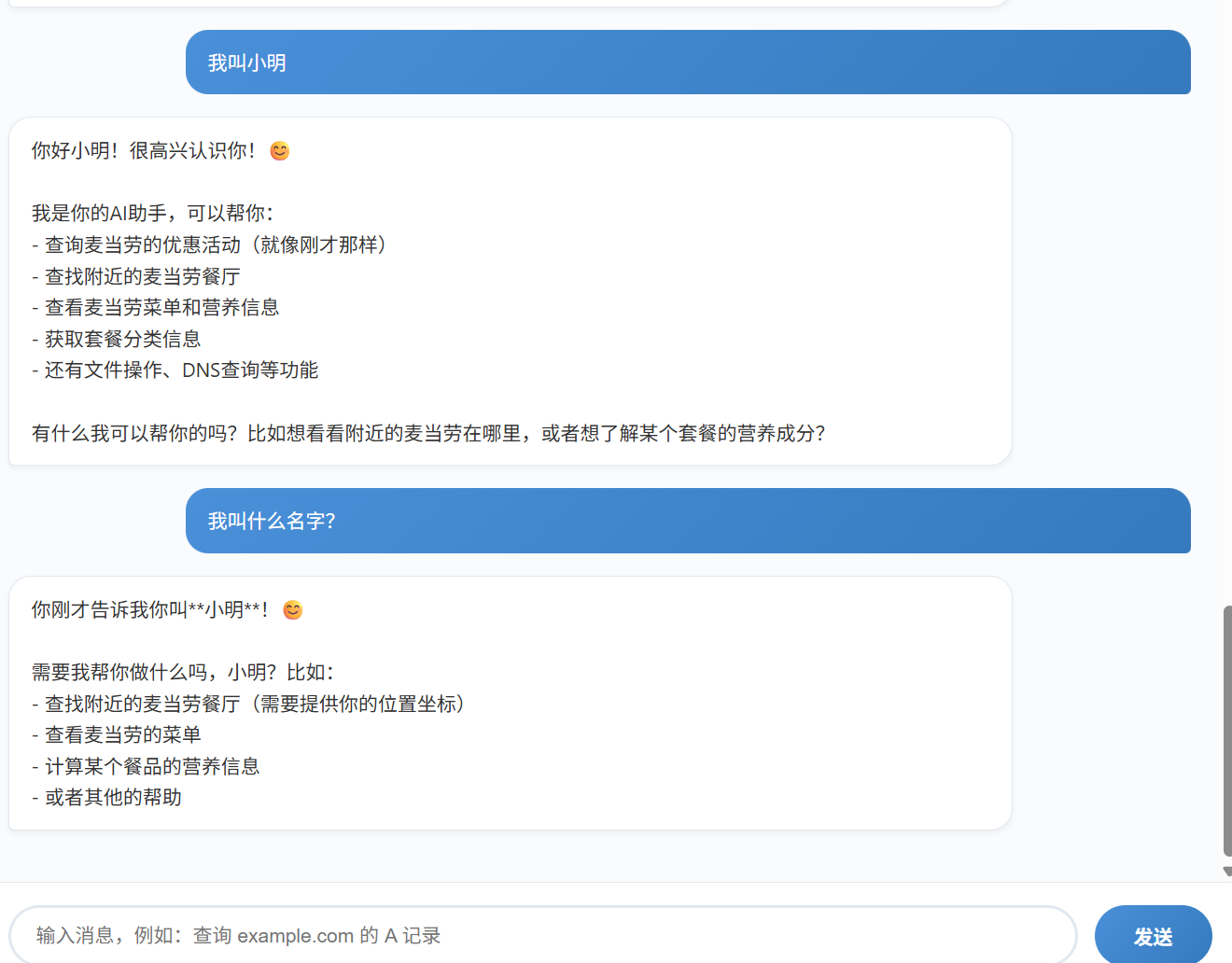
示例 6:记忆测试 用户 :我叫小明
Agent :你好小明!很高兴认识你。
用户 :我叫什么名字?
Agent :你叫小明呀,刚才告诉我的。
如何运行 1. 安装依赖 pip install langgraph langchain langchain-openai fastapi uvicorn jinja2 python-multipart fastmcp
2. 启动服务 cd 06_projects/agent_web_chat
3. 访问界面 打开浏览器访问 http://localhost:8000,即可开始与 Agent 对话。
总结与展望 通过这个项目,我深入理解了 LangGraph 的核心概念:
状态管理 :使用 TypedDict 定义状态,配合注解实现自动合并条件边 :tools_condition 实现了 LLM 自主决策是否调用工具持久化 :MemorySaver 提供了开箱即用的记忆能力循环工作流 :工具执行后自动回到聊天节点,形成闭环
未来可以扩展的方向:
🔮 更多 Skills :添加网络搜索、数据库查询、代码执行等功能
🌐 流式输出 :使用 WebSocket 实现打字机效果的流式响应
🔐 用户认证 :添加登录系统,支持多用户隔离
🧠 长期记忆 :接入向量数据库,实现跨会话的长期记忆
LangGraph 为构建复杂 AI 应用提供了强大的基础设施,值得一试。
参考链接

评论
0 条评论